El producto se llama PC-lint for C/C++, y se sabe que programadores que trabajan en empresas especializadas en software como Microsoft, Oracle y Adobe han estado comprando licencias actualizadas del producto para hacerlo disponible a sus programadores. Al empezar el tercer milenio, en agosto de 2000 la empresa Gimpel Software fundada 15 años atrás seguían anunciando en la revista Windows Developers Journal (y en otras revistas de programación) su principal producto como el más anunciado continuamente por más tiempo en la historia de la humanidad, con un anuncio en el cual puso su “reto # 599” (Bug of the Month, “bicho del mes”) invitando a los lectores de la revista -muchos de ellos programadores profesionales- a encontrar el error en el programa. El reto presentado por Gimpel Software, con el señalamiento de que este y todos los demás retos publicados eran muestras de lo que podía ser detectado por su paquete PC-lint y lo cual escapaba a los poderes de detección de muchos de los mejores compiladores del momento, se puede enunciar del modo siguiente tal y como apareció en la revista Windows Developers Journal:
PROBLEMA: Considérese el siguiente programa:
TABLA DE GIMPEL SOFTWARE:
| #include <stdio.h>
void print_sum (double a[], int n) { int i ; double sum = 0 ; for ( i = 0; i < n; i++ ) sum += a[i] ; printf( "Sum = %d\n", sum ); } int main() { double x[3] = { 1.0, 2.0, 3.0}; print_sum (x, 3); return 0; } |
La intención del programa es que imprima la suma de un array que consiste de tres elementos, pero no parece lograr su objetivo, ya que el compilador dice que la suma es igual a 0. ¿En dónde se encuentra el error?.
Y efectivamente, si se corre el programa anterior, se imprimirá en la ventana de resultados “Sum.=.0”. Cabe agregar que para corregir el programa-reto propuesto por Gimpel Software para lograr lo que se desea no es necesario aprender nuevos principios además de los que hemos visto ya previamente, el lector tiene en sus manos todos los elementos y herramientas para llevar a cabo manualmente el diagnóstico encontrando el fallo; pero esto supone que el lector mantiene firmemente en su mente los principios que se le han dado.
Y así como Gimpel Software presentó el anterior “reto” a los lectores de una revista del Windows Developers Journal, una revista mensual dirigida a programadores profesionales, ha estado presentando muchos otros retos -cientos y cientos de ellos- afirmando que en todos ellos el producto promocionado por Gimpel Software puede detectar en el código fuente problemas potenciales con mensajes de alerta que no son proporcionados por los compiladores (ningún compilador C por bueno que sea es capaz de anticipar todas las fuentes posibles de errores que se puedan dar sobre todo tratándose de errores de lógica ocultos en un código fuente elaborado correctamente sin errores de sintaxis). Al momento de ser publicada esta obra, en 2014, la empresa sigue vendiendo PC-lint, actualizado a la versión 9.0, acumulando 30 años en el mercado,
El hecho de que una empresa haya podido estar sacando propaganda por tanto tiempo presentando una amplia variedad de retos para entretener a los lectores -muchos de ellos programadores experimentados con años de experiencia- poniéndolos a pensar por horas o días (en algunos casos los errores metidos intencionalmente eran tan sutiles como difíciles de detectar) es quizá uno de los indicadores más claros de que el lenguaje C es algo que debe tomarse con seriedad, al igual que el aprendizaje del violín. Cualquiera puede tomar un violín y después de unos cuantos meses de práctica puede meterse como integrante de una banda de mariachis o bien instalarse en la plaza pública con un mono sosteniendo una taza o un pandero, pero no cualquiera puede dominar el violín para presentarse a ejecutar algo como el Concierto para Violín y Orquesta de Tschaikovsky en una sala de orquesta sinfónica. Y en programación al igual que en la música y en cualquier otro campo del saber humano, lo único que separa al programador profesional del novato es la práctica para la cual no hay substituto, esto además de tener la teoría bien fundamentada. Y eso es precisamente lo que se está tratando de lograr aquí, proporcionar una sólida fundamentación de la teoría. Corresponde al lector poner en práctica lo que aquí se está enseñando y procurar literatura en-línea como el Doctor Dobb's Journal para repasar la manera en la que ha ido evolucionando el lenguaje C y las cosas que se pueden lograr con dicho lenguaje.
Quizá uno de los temas que más causan confusión en la programación en lenguaje C es el de los punteros a funciones, los cuales pese a su manejo delicado son una de las capacidades más importantes disponibles en el lenguaje C, inexistente en la gran mayoría de los demás lenguajes de alto nivel. Y queremos tener firme este concepto en nuestras mentes antes de proceder adelante.
Podemos imaginar la representación binaria en la memoria RAM de un número flotante al cual en un sistema computacional relativamente modesto se le han asignado cuatro bytes para su codificación (32 bits en total) como cuatro bytes, con el primer byte puesto en la localidad 5FA3 de la memoria RAM y los siguientes tres bytes puestos en las siguientes localidades sucesivas 5FA4, 5FA5 y 5FA6 del RAM. Un puntero hacia el número flotante solo tiene que apuntar hacia la localidad 5FA3 porque tratándose de un número flotante el resto de la representación del número tiene que estar definido por los siguientes tres bytes puestos en las siguientes tres localidades del RAM. Igualmente podemos imaginar la representación binaria en la memoria RAM de un array de veinte elementos de tipo char como veinte bytes, con el primer byte puesto en la localidad C819 y los siguientes 19 bytes puestos en las siguientes localidades sucesivas C81A, C81B, C81C, y así sucesivamente. Un puntero hacia este array solo tiene que apuntar hacia la localidad C819 en donde está puesto el primer caracter del array. En ambos casos, al fin y al cabo se trata de simples variables, datos codificacos en sistema binario.
¿Pero qué de una función? ¿Hacia dónde tiene que apuntar un puntero de función?
Un puntero de función es, en cierto modo, un nuevo tipo de dato. Aunque una función no es una variable, de cualquier modo ocupará cierto espacio físico dentro de la memoria RAM, un espacio físico al cual se le puede asignar un puntero. ¿Pero hacia dónde debe apuntar el puntero? Por definición, el domicilio que se le asigna a un puntero de función es el punto de entrada de la función. Considérese la siguiente función producto() que nos regresa el producto de dos números a y b:
producto(int a, int b)
{
return a*b;
}
Si el lector trata de visualizar el punto de entrada de la función como la letra “p” con la cual empieza el nombre de la función, su razonamiento estará completamente errado, porque el punto de entrada de la función no se refiere a la función como está escrita en el código fuente en C, sino a la función ya compilada, en lenguaje de máquina, la cual será ejecutada por el procesador CPU de la máquina. La manera más fácil de entenderlo es empezando con una función que no recibe argumentos ni regresa valor alguno, una función cuyo prototipo tenga el siguiente aspecto:
void sonido(void);
Supondremos que la definición de la función sonido() invoca una función del hardware como la bocina, y el propósito de la función es hacer sonar un “bip” quizá como un llamado de atención al usuario para indicarle que la ejecución de algo ha terminado o que se está a la espera que tome alguna acción desde el teclado o el Mouse. En lenguaje de máquina, desde el punto de vista del hardware, esto se puede lograr posiblemente con unas cuatro o cinco instrucciones en lenguaje de máquina, con la primera instrucción ejecutable puesta en la localidad de la memoria 07B2 y las siguientes instrucciones puestas en las localidades de memoria 07B3, 07B4 y 07B5. Se trata de un programa ejecutable en lenguaje de máquina que empieza con el procesador CPU tomando la primera instrucción de la localidad de la memoria 07B2, tomando la segunda instrucción de la localidad de la memoria 07B3, y así sucesivamente (supondremos que en el programa en lenguaje de máquina no hay brincos condicionados o incondicionales hacia otras localidades y que todo se lleva a cabo secuencialmente). Queda claro entonces que para la función sonido() su punto de entrada se encuentra en la localidad de la memoria 07B2, es en donde se comienza a ejecutar el programa en lenguaje de máquina en algún procesador tipo Intel, AMD o algo similar.
¿Y qué de una función que toma argumentos y regresa algún valor? El principio sigue siendo el mismo. Una vez que la función ha sido compilada, se ejecutará en lenguaje de máquina tomándose la primera instrucción que se debe encontrar en alguna localidad de la memoria RAM. Conforme el procesador va ejecutando cada instrucción en lenguaje de máquina de la función, cuando requiera tomar algún argumento o argumentos se dirigirá hacia otra porción de la memoria RAM en donde se reservó espacio suficiente para almacenar los argumentos con los que debe trabajar la función. Si se requiere regresar algún valor, el valor regresado será puesto por el programa en lenguaje de máquina en algún otro lugar de la memoria RAM de donde podrá ser tomado por otras funciones o por la función principal main(). Pero el punto de entrada de la función sigue siendo la localidad en la memoria RAM en donde empieza la ejecución de la función cuando ya ha sido compilada y convertida a lenguaje de máquina.
Así pues, el domicilio que es asignado a un puntero de función es el punto de entrada de la función. Y este puntero puede ser utilizado en lugar del nombre de la función. Y por la manera en la cual se define y se maneja un puntero a una función, por convención se puede afirmar que:
Un puntero hacia una función es considerado como una variable, considerado como una variable de puntero o simplemente una variable puntero.
Todo esto a su vez permite que funciones completas puedan ser pasadas como argumentos a otras funciones. Conforme cada función en un programa C es compilada, el código fuente es transformado a código objeto estableciéndose un punto de entrada para cada código objeto. Cuando se hace una invocación a una función cuando el programa se está ejecutando, se lleva a cabo un “llamado” en lenguaje de máquina a su punto de entrada. Por lo tanto, un puntero a una función contiene el domicilio en la memoria del punto de entrada de la función.
Igualmente importante es el hecho de que en la programación en código fuente, el domicilio de una función es obtenido usando el nombre de la función sin paréntesis ni argumentos. Esto es semejante a la manera en la cual se obtiene el domicilio de un array cuando se utiliza únicamente el nombre del array sin índices. De este modo, si la función es:
ejemplo(int a, char x)
el domicilio de la función (definido como el punto de entrada de la función) se obtiene escribiendo simplemente:
ejemplo
Pero lo más importante... ¿cómo declaramos un puntero a una función? Supóngase que queremos declarar a *p como el puntero a una función que nos regresa un dato de tipo double. La sintaxis para declarar dicho puntero es:
double (*p)()
Como muestra de estas convenciones, considérese el siguiente programa poniendo atención especial en las declaraciones:
#include <stdio.h>
#include <string.h>
void cotejar(char *a, char *b, int (*cmp) ());
main()
{
char hilera1[80], hilera2[80];
int (*p) (); /* declaracion de puntero de funcion */
p = strcmp; /* asignacion de domicilio de funcion a puntero */
printf("dame la primera hilera: ");
gets(hilera1);
printf("dame la segunda hilera: ");
gets(hilera2);
cotejar(hilera1, hilera2, p);
return 0;
}
void cotejar(char *a, char *b, int (*cmp)())
{
printf("probando igualdad de hileras\n");
if(!(*cmp) (a, b)) printf("hileras iguales");
else printf("hileras desiguales");
}
La ejecución del programa, una vez compilado a código ejecutable, no tiene mayor chiste. Se le piden sucesivamente al usuario dos hileras de texto. Usando la función C de biblioteca strcmp() (string compare) se comparan las hileras, si las hileras son iguales se imprime el mensaje “hileras iguales”, y si no lo son se imprime el mensaje “hileras desiguales”.
Examinando el programa en mayor detalle, vemos que un puntero de función es declarado usando el enunciado:
int (*p)();
Cuando la función cotejar() es invocada, se le pasan como parámetros dos punteros de caracter (uno para cada hilera de texto):
char *a
char *b
y un puntero de función como tercer argumento:
int (*cmp)()
Obsérvese la manera en la cual el puntero de función es declarado. Es necesario usar un método semejante cuando se declaran otros punteros de función, excepto que el tipo de retorno puede ser diferente. Si se desea, para ser un poco más riguroso y más elegante se pueden especificar los tipos de los parámetros de la función, aunque ello no es indispensable. Los paréntesis en torno a *cmp son requeridos para que el compilador pueda interpretar correctamente el enunciado; sin tales paréntesis puestos el compilador se confundiría. En efecto, considérese el siguiente enunciado:
char *gets();
Esta declaración nos dice que la función C de biblioteca gets() (get string) es una función de la forma “puntero hacia un tipo char”; esto es, nos regresa un puntero de tipo caracter. En cambio el enunciado:
char (*foop)();
nos dice que foop es un puntero a una función que es de tipo char.
Una vez dentro de la función cotejar(), podemos ver cómo la función C de biblioteca strcmp() es llamada para ser ejecutada. El enunciado:
(*cmp) (a,b)
se encarga de hacer la invocación a la función, en este caso trcmp(), a la cual se está apuntando por cmp con los argumentos a y b. De nueva cuenta, los paréntesis entre los cuales está puesto *cmp son necesarios. Esto también representa la forma general en donde se usa un puntero de función para invocar la función hacia la cual se está apuntando. Obsérvese que es posible invocar a cotejar() usando strcmp() directamente, de la siguiente manera:
cotejar(hilera1, hilera2, strcmp);
con lo cual se elimina la necesidad de usar una variable de puntero adicional.
Podemos preguntarnos qué es lo que se espera ganar escribiendo un programa de esta manera, máxime que en el ejemplo que se ha dado no se ha ganado nada y en cambio sí se ha introducido confusión en la lectura del código. La respuesta es que se les puede dar a los punteros de función varios usos prácticos, y uno de ellos es la creación de lo que se conoce como una función genérica que puede ser usada para llevar a cabo el mismo tipo de operación sobre tipos distintos de datos en lugar de estar limitada a un solo tipo de dato. Podemos darnos una idea de ello en la siguiente versión expandida del programa anterior en la cual la función genérica cotejar() puede checar no solo la igualdad alfabetica de dos hileras sino también la igualdad numérica de dos números, con el simple hecho de invocarla con una función diferente de comparación:
#include <ctype.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
/* Declaracion de prototipos */
void cotejar(char *a, char *b, int(*cmp)());
int compnum(char *a, char *b);
main(void)
{
char hilera1[80], hilera2[80];
gets(hilera1);
gets(hilera2);
if(tolower(*hilera1) <= 'z' && tolower(*hilera1) >= 'a')
cotejar(hilera1, hilera2, strcmp);
else
cotejar(hilera1, hilera2, compnum);
return 0;
}
void cotejar(char *a, char *b, int(*cmp)() )
{
printf("probando igualdad de hileras\n");
if(!(*cmp) (a,b)) printf("hileras iguales");
else printf("hileras desiguales");
}
compnum(char *a, char *b)
{
if(atoi(a)==atoi(b)) return 0;
else return 1;
}
En C++, la extensión orientada-a-objetos del lenguaje C, podemos lograr un propósito parecido usando el mismo nombre de una función para el procesamiento de tipos de datos diferentes con algo que se llama el sobrecargado de funciones, pero esto tiene que esperar a que veamos cómo se lleva a cabo tal cosa.
Al introducir el tema de punteros a funciones, la cosa se ha puesto más compleja, y es por ello que conviene hacer un repaso de términos y definiciones para dejar en claro las diferencias que hay entre declaraciones elaboradas. En general, cuando hacemos una declaración, el nombre (o identificador) que usamos puede ser modificado anexándole un modificador:
| Modificador | Significado |
| * | Indica un puntero |
| ( ) | Indica una función |
| [ ] | Indica un array |
Hemos visto que C permite usar más de un modificador a la vez permitiéndonos crear una variedad de formas como lo indican los siguientes ejemplos:
int matriz[15][15]; /* un array de arrays de tipo int */
int **ptr; /* un puntero a un puntero de tipo int */
int *miembros[30] /* un array de 30 punteros a int */
int (*lopitos)[20]; /* un puntero a un array de 20 elementos int */
int *foo[6][4];
/* un array de 6 elementos de punteros a un array de cuatro elementos int */
int (**equis)[3][4] /* un puntero a un array 3x4 de int */
Los pasos a seguir para poder desmenuzar el orden en el cual se deben aplicar los modificadores para obtener una interpretación correcta en cada caso se pueden resumir en tres reglas:
(1) Entre más cercano esté un modificador al identificador, mayor será su prioridad.
(2) Los modificadores [ ] y ( ) tienen una prioridad mayor que el asterisco.
(3) Los paréntesis usados para agrupar partes de una expresión tienen la mayor prioridad de todas.
De este modo, en la expresión:
int *foo[6][4];
el asterisco y [6] están ambos adyacentes a foo y por lo tanto tienen una prioridad más alta que [4] de acuerdo a la primera regla. Y el [6] tiene una mayor prioridad que el asterisco de acuerdo a la segunda regla. Por lo tanto, foo es un array de seis elementos (primer modificador) de punteros (segundo modificador) hacia un array de cuatro elementos (tercer modificador) de tipo int (tipo declarado).
En la siguiente declaración:
int (*fuu)[6][4];
los paréntesis hacen que el modificador asterisco tenga la primera prioridad, haciendo que fuu sea un puntero de acuerdo a la descripción dada.
La aplicación de las reglas también produce los siguiente tipos:
char *fump() /* funcion que regresa un puntero de tipo char */
char (* frump) (); /* puntero a una función que regresa un char */
char *flump()[3];
/* funcion que regresa un puntero a un array de 3 elementos de tipo char */
char *flimp[3]();
/* un array de 3 elementos de punteros a una funcion que regresa un char */
Si metemos estructuras struct en el panorama anterior, las posibilidades y combinaciones hacen que el asunto sea merecedor de una tesis de doctorado en informática.
Hay otra manera de poder llegar correctamente la interpretación que debemos dar a los punteros a funciones en expresiones complejas. Si usamos como punto de partida la siguiente definición de un puntero a una función:
void (*puntero_funcion)();
una buena manera de comenzar es empezar desde en medio y trabajar saliendo hacia afuera. “Empezar desde en medio” significa comenzar con el nombre de la variable que en este caso es puntero_funcion; y “saliendo hacia afuera” significa buscar hacia la derecha el artículo más cercano (no hay nada en este caso, el paréntesis derecho detiene el proceso), y buscar entonces hacia la izquierda (un símbolo de puntero indicado con el asterisco), yendo hacia la derecha en donde encontramos una lista de argumentos vacía que indica una función, yendo entonces hacia la izquierda encontrando void que nos dice que la función no tiene un valor de retorno. Este movimiento derecha-izquierda-derecha funciona en la mayoría de las situaciones.
Repasando: “empezar desde en medio” (“puntero_funcion es ...”), ir hacia la derecha (no hay nada allí, nos detiene el paréntesis derecho), ir hacia la izquierda encontrando el asterisco (“... un puntero a ...”), ir a la derecha y encontrar la lista vacía de argumentos (“... una función ...”), ir a la izquierda y encontrar void (que nos regresa un nulo), con lo cual juntándolo todo se tiene la frase “puntero_funcion es un puntero a una función que nos regresa un nulo”. Si aún nos preguntamos el por qué *puntero_funcion requiere paréntesis, si no se incluyeran entonces el compilador leería:
void *puntero_funcion();
con lo cual se estaría declarando una función en vez de definirse una variable. Podemos imaginar que un compilador recorre una línea similar de razonamiento cuando trata de determinar el significado de una declaración o definición. Necesita los paréntesis para toparse con ellos invirtiendo así su dirección de movimiento para así poder regresar en sentido contrario hacia la izquierda encontrando el asterisco en lugar de continuar moviéndose hacia la derecha encontrando la lista vacía de argumentos.
Una vez que hemos entendido cómo trabaja la sintaxis de declaraciones, podemos crear otras cosas más complicadas.
PROBLEMA: Determínese lo que representan en C cada una de las siguientes definiciones:
void *(*(*fp1)(int))[10];
float (*(*fp2)(int,int,float))(int);
typedef double (*(*(*fp3)())[10])();
(*(*f4())[10])();
Para la primera definición decimos “fp1 es un puntero a una función que toma como argumento un entero int y que regresa un puntero a un array de diez punteros nulos”. Para la segunda definición decimos “fp2 es un puntero a una función que toma tres argumentos (int, int y float) y regresa un puntero a una función que toma un argumento entero y regresa un float”. Si se están creando muchas definiciones complicadas, posiblemente queramos usar un typedef como en la tercera definición que nos ahorra volver a escribir cada vez en su totalidad la definición complicada. Para la tercera definición decimos “Un fp3 es un puntero a una función que regresa un puntero a un array de diez punteros a funciones que no toman argumentos y que regresan datos de tipo double”. Observamos que la cuarta definición es una declaración de función en lugar de una definición de variable. En la cuarta definición decimos “f4 es una función que regresa un puntero a un array de diez punteros a funciones que regresan datos”. ¿Pero qué tipo de datos? (obsérvese que no se especifica el tipo de retorno).En una situación así, y por convención predeterminada, C supone que son de tipo int. O sea que en la cuarta definición debemos decir “f4 es una función que regresa un puntero a un array de diez punteros a funciones que regresan ints”.
Veremos a continuación un programa algo más amplio que los ejemplos breves que hemos visto hasta ahora, en el cual definimos diez funciones f1(), f2(), etcétera, además de la función principal main():
#include <stdio.h>
#include <conio.h> /* Requerido para usar funcion getche() */
#include <math.h> /* Requerido para la funcion matematica sqrt() */
#include <ctype.h> /* Requerido para usar la funcion toascii() */
/* DECLARACION DE PROTOTIPOS DE FUNCIONES USADAS EN EL PROGRAMA */
char f1(int x);
double f2(int x);
float f3(int x, int y), f4(int x);
void f5(char x[80]);
void f6(char x[80]);
void f7(char x[80]);
void f8(char *p1, int *p2, float *p3);
float *f9(void);
float *f10(void);
/* FUNCION PRINCIPAL MAIN */
void main(void)
{
int i, j, k, q, r, s, t;
float x, y, z;
char ch, frase[80], *ptr;
char str[] = "Programar en C es divertido";
float *X;
printf("\nDame un entero positivo para darte el caracter ASCII: ");
scanf("%d", &i);
ch = f1(i);
printf("Al entero %d le corresponde el caracter %c", i, ch);
printf("\n\nDame un entero para darte su raiz cuadrada: ");
scanf("%d", &i);
printf("El entero %d tiene raiz cuadrada %lg", i, f2(i));
printf("\n\nDame un numero entero pitagorico: ");
scanf("%d", &i);
printf("Dame otro numero entero pitagorico: ");
scanf("%d", &j);
z = f3(i, j);
printf("El modulo complejo de %d y %d es %f", i, j, z);
printf("\n\nDame un entero mayor que cero: ");
scanf("%d", &k);
x = f4(k);
printf("El logaritmo base 10 de %d es %f\n", k, x);
f5(str);
f6(str);
f7(str);
ch = getch();
ch = 'U';
i = -3067;
x = 45.0349;
f8(&ch, &i, &x);
/* Al invocar la funcion f8() le pasamos los tres DOMICILIOS */
/* usando &ch, &i, &x como argumentos */
X = f9();
printf("\n\nEl valor *X almacenado bajo el puntero X es %f", *X);
X = f10();
printf("\nEl valor *X almacenado bajo el puntero X es %f", *X);
/* Todas las funciones de biblioteca regresan algun valor, y */
/* ello incluye las funciones de biblioteca printf() y scanf() */
/* como puede verse abajo */
printf("\n\nLa funcion printf() con los tres argumentos:\n");
i = printf("%c, %d, %f", 'M', 37, 65.38);
printf("\nregresa el valor %d, la cantidad de caracteres impresa", i);
printf("\n\nLa funcion scanf() pidiendo cuatro argumentos enteros:\n");
i = scanf("%d %d %d %d", &q, &r, &s, &t);
printf("regresa el valor %d, la cantidad de argumentos leida", i);
/* Al hacer referencia al nombre de una funcion sin escribir ni */
/* los argumentos ni los parentesis de la funcion entonces se nos */
/* regresa el domicilio asignado a la funcion como punto de entrada */
/* como se ve a continuación */
printf("\n\nEl domicilio de la funcion f1() es %p", f1);
printf("\nEl domicilio de la funcion f2() es %p", f2);
printf("\nEl domicilio de la funcion f5() es %p", f5);
flushall();
/* Aqui limpiamos el "buffer del teclado" en preparacion */
/* para los siguientes ejemplos */
/* USO NORMAL (DIRECTO) DE LA FUNCION gets() */
printf("\n\nDame una frase corta: ");
gets(frase);
printf("La frase es \"%s\"", frase);
/* USO DEL VALOR DE RETORNO DADO POR LA FUNCION gets() */
printf("\nDame otra frase corta: ");
ptr = gets(frase);
/* La funcion gets() nos regresa un puntero que apunta hacia */
/* el lugar en donde esta almacenado el primer caracter de */
/* la hilera, el cual pasamos a la variable de puntero ptr */
printf("La frase es \"%s\"", ptr);
}
/* DEFINICION DE LAS FUNCIONES USADAS EN EL PROGRAMA */
char f1(int x)
{
char ch;
ch = toascii(x);
/* La funcion toascii() convierte un entero a formato ASCII */
return ch;
}
double f2(int x)
{
double y, z;
y = (double) x; /* Promovemos el parametro x de int a doble */
z = sqrt(y);
return z;
}
float f3(int x, int y)
{
float z;
z = sqrt( (float) ( (x*x) + (y*y) ) );
return z;
}
float f4(int x)
{
double y;
y = log10( (float) x);
return y;
}
void f5(char str[80])
{
printf("\nf5(): %s", str);
}
void f6(char str[])
{
printf("\nf6(): %s", str);
}
void f7(char *str)
{
printf("\nf7(): %s", str);
}
void f8(char *p1, int *p2, float *p3)
{
printf("\n\nEl valor *p1 en el domicilio\n");
printf("%p dentro de f8() es %c",p1, *p1);
printf("\n\nEl valor *p2 en el domicilio\n");
printf("%p dentro de f8() es %d", p2, *p2);
printf("\n\nEl valor *p3 en el domicilio\n");
printf("%p dentro de f8() es %f", p3, *p3);
}
float *f9(void)
{
float temp = 458.0039;
float *ptrf = &temp;
/* Declaracion e inicializacion de la variable */
/* de puntero ptrf de tipo float */
return ptrf;
/* La funcion f9() regresa el domicilio que */
/*corresponde al puntero ptrf de tipo float */
}
float *f10(void)
{
static float temp = 458.0039;
/* Declaramos a la variable interna 'temp' con el especificador */
/*'static' como una variable estatica que puede retener su valor */
/* mas reciente aun cuando la funcion haya terminado su labor */
float *ptrf = &temp;
/* Declaracion e inicializacion de la variable de puntero ptrf */
return ptrf;
/* La funcion f10() nos regresa el domicilio que corresponde */
/* al puntero ptrf, el cual apunta hacia la variable estatica Y */
}
El programa dado arriba es un programa interactivo. Si se ejecuta, la salida en la ventana DOS simulada por el entorno integrado IDE puede ir produciendo algo como lo siguiente:

El resto de la ejecución interactiva puede producir algo como lo siguiente:
| La funcion scanf() pidiendo cuatro argumentos enteros: 45 78 Q 300 regresa el valor de 2, la cantidad de argumentos leida El domicilio de la funcion f1() es 2357:0313 El domicilio de la funcion f2() es 2357:0332 El domicilio de la funcion f5() es 2357:03FE Dame una frase corta: Bienvenido al lenguaje C La frase es "Bienvenido al lenguaje C" Dame otra frase corta: Me llamo Armando La frase es "Me llamo Armando" |
En el programa anterior además de la función principal main() se han definido diez funciones sencillas, y el hecho de que sean funciones sencillas que no requieren más de unas tres o cuatro líneas de código cada una permite poner todo dentro de un solo archivo que debe ser compilado a un archivo ejecutable cada vez que se tenga que actualizar el gran programa. ¿Pero qué tal si se trata de algo más complicado, como un programa para el manejo de una base de datos de una empresa automotriz que maneja inventarios grandes? No es difícil imaginar un programa que contenga unas cien funciones, cada una con unas cien líneas de código en promedio dando un total de 10 mil líneas de código. Darle mantenimiento a algo así puede resultar un verdadero dolor de cabeza, y se antoja deseable romper el archivo original del código fuente en varios archivos separados, lo cual permite darle mantenimiento a cada archivo. Cuando se tiene que llegar a estos extremos, estamos hablando ya de algo que no es un simple programa fuente guardado en un archivo sencillo, se trata de un proyecto en el cual deben colaborar en forma estrecha dos o más programadores. La elaboración de un sistema operativo como Windows 8 sería el mejor ejemplo de cómo se pueden complicar las cosas. El manejo de proyectos es algo que se tiene que tratar por separado junto con las herramientas con las que hay que familiarizarse para poder graduar a las grandes ligas en el campo de la informática, y dejaremos ese tema pendiente en esta entrada.
Los puntos que nos interesa resaltar del programa anterior son los siguientes:
(1) No debe quedar duda alguna de que dada una función C cualquiera, por ejemplo funcion(), escribir el nombre de la misma sin los paréntesis usados para la lista de argumentos, o sea escribir simplemente funcion, producirá el punto de entrada a la función, esto es, el domicilio a partir del cual empieza el programa ejecutable que efectúa en lenguaje de máquina las instrucciones que fueron codificadas en el lenguaje de alto nivel. Es por ello que cada una de las tres instrucciones:
printf("\n\nEl domicilio de la funcion f1() es %p", f1);
printf("\nEl domicilio de la funcion f2() es %p", f2);
printf("\nEl domicilio de la funcion f5() es %p", f5);
imprime respectivamente lo siguiente en sistema hexadecimal:
El domicilio de la funcion f1() es 2357:0313
El domicilio de la funcion f2() es 2357:0332
El domicilio de la funcion f5() es 2357:03FE
Obsérvese que al usar printf() para poder imprimir el domicilio de la variable de puntero a función, entre las dobles comillas que delimitan el texto que será impreso hay que usar el código de formato %p.
(2) En todos los casos en los que pasamos un argumento de hilera a una funcion, al ejecutar la función le estamos pasando realmente el domicilio del primer caracter de la hilera, el cual siempre se obtiene automaticamente al escribir el nombre del array sin los parentesis cuadrados, con lo cual basta con escribir:
f7(str);
sin tener que escribir:
f7(str[ ]);
(3) Para demostrar el inciso anterior, se han puesto en el programa tres funciones distintas, f5(), f6() y f7(), en las cuales le pasamos la misma hilera str a las tres funciones:
void f5(char str[80]) { ... }
void f6(char str[]) { ... }
void f7(char *str) { ... }
y en la impresión producida en cada caso se obtiene exactamente el mismo resultado:
f5(): Programar en C es divertido
f6(): Programar en C es divertido
f7(): Programar en C es divertido
La tercera manera de pasar argumentos de hilera a funciones, usada en la función f7(), es la forma clásica preferida por los programadores profesionales.
(4) Las dos funciones f9() y f10() parecen hacer lo mismo y no parece haber diferencia alguna entre ambas. En realidad, hay una diferencia sutil de la que únicamente el programador se dará cuenta, El usuario final jamás llegará a detectar diferencia alguna.
Como puede verse en la declaración de los prototipos de las funciones del programa anterior, la funcion f1() recibe un entero como argumento y regresa un caracter; la función f2() recibe un entero y regresa un flotante de doble precisión; las funciones f3() y f4() ambas regresan un flotante y por lo tanto pueden ser declaradas en una misma línea, sin embargo la primera toma dos argumentos de tipo entero mientras que la segunda recibe uno solo; la función f5() no regresa nada pero puede recibir como argumento una hilera de tipo char de hasta 80 caracteres; la función f6() tiene el mismo proposito que f5() excepto que en la definicion tendra un parametro de hilera sin especificarse la cantidad de caracteres a ser usados; la función f7() tiene el mismo propósito que f5() y f6() excepto que en la definicion tendrá declarado como parametro formal una variable de puntero; la función f8() no regresa nada pero tiene declarados como argumentos tres punteros uno de tipo char, otro de tipo int y otro de tipo float. Al momento de invocar a f8() le tenemos que pasar tres domicilios que contengan datos compatibles con el tipo que corresponda a la variable de puntero respectiva; la función f9() no recibe argumento alguno pero nos regresa un puntero de tipo float, efectuando de este modo algo inverso a la función f8(); y por último la función f10() actúa en forma semejante a f9() como puede intuírse en la similitud de los prototipos. Y de hecho ambas funciones f9() y f10() tienen casi el mismo código, la única diferencia es que en la función f10() declaramos la variable interna temp como estática (static) mientras que en f9() no lo hacemos. Esto tiene una consecuencia, ya que al terminar la ejecucion de la funcion f9() todas sus variables locales son destruidas, de modo tal que aunque la variable de puntero hacia el domicilio al que apuntaba la variable de puntero local ptrf siga allí, el valor al cual apuntaba ya no existe. En tales casos, para preservar ese valor se tiene que recurrir a una variable estatica declarada dentro de la funcion f10() con el especificador 'static', con lo cual el compilador creara espacio permanente en la memoria para dicha variable como si fuese una variable global, aunque sin embargo solo podra ser inicializada y modificada dentro de la funcion f10().
Obsérvese que con las siguientes dos instrucciones dentro de la función principal main():
i = printf("%c, %d, %f", 'M', 37, 65.38);
i = scanf("%d %d %d %d", &q, &r, &s, &t);
se comprueba que funciones de biblioteca de entrada/salida tales como printf() y scanf() regresan algo siempre, aunque tal hecho solo sea usado en raras ocasiones excepto por programadores especializados.
En el programa se ha utilizado una función de biblioteca llamada flushall() (evacuar todo) que se encuentra disponible en muchas bibliotecas, usada para “purgar” todo lo que pueda haber en la memoria buffer del teclado, en preparación para la ejecución de instrucciones posteriores (si no se lleva a cabo esta limpieza, dependiendo de las instrucciones precedentes en un programa se corre el riesgo de que se impriman cosas indeseadas en las instrucciones posteriores en las cuales se interactúe con el teclado). Se ha usado también la función de biblioteca gets() (get string, obtener hilera) que toma una hilera del dispositivo de entrada del sistema, generalmente un teclado. Puesto que una hilera introducida desde el teclado, que puede ser cualquier hilera (de cualquier tamaño), no tiene una longitud predeterminada, gets() necesita una manera de saber cuándo parar. Su método es continuar leyendo caracteres hasta que se llega a un caracter de línea nueva (“\n”) que se genera cuando el usuario oprime la tecla de entrada [Enter]. Toma todos los caracteres antes (pero no incluyendo) de la línea nueva, anexa un caracter nulo (“\0”) y le entrega la hilera al programa que invoca dicha función, lo cual se logra en nuestro programa con una instrucción como la siguiente con la cual se toma la hilera del teclado y se almacena en la variable de hilera “frase”:
gets(frase);
¿Y qué ocurre cuando se ejecuta la siguiente instrucción?:
ptr = gets(frase);
Pues se regresa un puntero hacia el primer caracter con el que inicia la hilera (recuérdese que toda hilera, que viene siendo es un array de caracteres, tiene un nombre, y el nombre de la hilera es un puntero, que apunta hacia el domicilio en donde está almacenado el primer byte que representa al primer caracter de la hilera).
Si bien en el programa anterior hay una función que recibe como argumentos tres punteros de tipos distintos:
void f8(char *p1, int *p2, float *p3);
y hay dos funciones que regresan punteros de tipo float:
float *f9(void);
float *f10(void);
por otro lado en todo el programa no hay punteros a funciones. Tomaremos el programa anterior, y en una segunda versión del programa le haremos unos cambios introduciendo en la nueva versión punteros a funciones:
#include <stdio.h>
#include <conio.h>
#include <math.h>
#include <ctype.h>
/* DECLARACION DE PROTOTIPOS DE FUNCIONES USADAS EN EL PROGRAMA */
char f1(int x);
double f2(int x);
float f3(int x, int y), f4(int x);
void f5(char x[80]);
void f6(char x[80]);
void f7(char x[80]);
void f8(char *p1, int *p2, float *p3);
float *f9(void);
float *f10(void);/
void main(void)
{
int i, j, k, q, r, s, t;
float x, y, z;
char ch, str[] = "Programar en C es divertido";
float *X;
/* DECLARACION DE VARIABLES PUNTEROS A FUNCIONES */
char (*F1)(int x);
/* F1 es el puntero a una funcion que toma un argumento */
/* de tipo int y nos regresa un valor de tipo char */
double (*F2)(int x);
/* F2 es el puntero a una funcion que toma un argumento */
/* de tipo int y nos regresa un valor de tipo double */
float (*F3)();
/* F3 es el puntero a una funcion que nos regresa un valor */
/* de tipo float. Observese que no estamos declarando una */
/* lista de argumentos, con lo cual estamos generalizando la */
/* capacidad del puntero para tomar una funcion de tipo float */
/* con una cantidad cualesquiera de argumentos de cualquier tipo */
void (*F4)();
/* F4 es el puntero a una funcion que tome cualquier tipo o */
/* cantidad de argumentos pero que no nos regrese nada */
float *( (*F5)() );
/* Observese que F5 es el puntero a una funcion que nos regresa */
/* un valor de puntero que apunta hacia un valor de tipo float */
printf("\nDame un entero positivo para darte el caracter ASCII: ");
scanf("%d", &i);
F1 = f1;
/* Inicializacion del puntero a funcion F1 con el domicilio de la
/* funcion f1() */
ch = F1(i);
printf("Al entero %d le corresponde el caracter %c", i, ch);
printf("\n\nDame un entero para darte su raiz cuadrada: ");
scanf("%d", &i);
F2 = f2;
/* Inicializacion del puntero a funcion F2 con el domicilio */
/* de la funcion f2() */
printf("El entero %d tiene raiz cuadrada %lg", i, F2(i));
printf("\n\nDame un numero entero pitagorico: ");
scanf("%d", &i);
printf("Dame otro numero entero pitagorico: ");
scanf("%d", &j);
F3 = f3;
/* Inicializacion del puntero a funcion F3 con el domicilio */
/* de la funcion f3(), la cual toma DOS ARGUMENTOS */
z = F3(i, j);
printf("El modulo complejo de %d y %d es %f", i, j, z);
printf("\n\nDame un entero mayor que cero: ");
scanf("%d", &k);
F3 = f4;
/* Inicializacion del puntero a funcion F3 con el domicilio de la función */
/* f4(), la cual toma UN SOLO ARGUMENTO. Puesto que dejamos */
/* abierta la cantidad de argumentos a ser tomada por el puntero a la */
/* funcion F3, pudo tomar aqui un solo argumento para pasarlo a f4() */
/* y pudo tomar anteriormente dos argumentos para pasarlos a f3() */
x = F3(k);
printf("El logaritmo base 10 de %d es %f\n", k, x);
F4 = f5;
/* Inicializacion del 'puntero a funcion' F4 con el domicilio de */
/* la funcion f5() */
F4(str); /* Se ejecuta la funcion F4() con la hilera str */
F4 = f6;
/* Inicializacion del 'puntero a funcion' F4 con el domicilio de */
/* la funcion f6 */
F4(str); /* Se ejecuta la funcion F4 con la hilera str */
F4 = f7;
/* Inicializacion del 'puntero a funcion' F4 con el domicilio de */
/* la funcion f7 */
F4(str);
/* En todos los casos en los que pasamos un argumento de hilera */
/* a una funcion estamos pasando realmente el domicilio del primer */
/* caracter de la hilera, el cual siempre se obtiene automaticamente */
/* al escribir el nombre del array sin los parentesis cuadrados */
ch = getch();
ch = 'U';
i = -3067;
x = 45.0349;
F4 = f8;
/* Inicializacion del puntero a funcion F4 con el domicilio */
/* de la funcion f8() */
F4(&ch, &i, &x);
/* Al invocar la funcion f8() a traves del puntero F4 le pasamos */
/* los tres DOMICILIOS &ch, &i, &x como argumentos */
F5 = f9;
/* Inicializacion del 'puntero a funcion' F5 con el domicilio */
/* de la funcion f9() */
X = F5();
printf("\n\nEl valor *X almacenado bajo el puntero X es %f", *X);
F5 = f10;
/* Inicializacion del 'puntero a funcion' F5 con el domicilio */
/* de la funcion f10 */
X = F5();
printf("\nEl valor *X almacenado bajo el puntero X es %f", *X);
}
/* DEFINICION DE LAS FUNCIONES USADAS EN EL PROGRAMA */
char f1(int x)
{
char ch;
ch = toascii(x);
return ch;
}
double f2(int x)
{
double y, z;
y = (double) x;
z = sqrt(y);
return z;
}
float f3(int x, int y)
{
float z;
z = sqrt( (float) ( (x*x) + (y*y) ) );
return z;
}
float f4(int x)
{
double y;
y = log10( (float) x);
return y;
}
void f5(char str[80])
{
printf("\nf5(): %s", str);
}
void f6(char str[])
{
printf("\nf6(): %s", str);
}
void f7(char *str)
{
printf("\nf7(): %s", str);
}
void f8(char *p1, int *p2, float *p3)
{
printf("\n\nEl valor *p1 en el domicilio\n");
printf("%p dentro de f8() es %c",p1, *p1);
printf("\n\nEl valor *p2 en el domicilio\n");
printf("%p dentro de f8() es %d", p2, *p2);
printf("\n\nEl valor *p3 en el domicilio\n");
printf("%p dentro de f8() es %f", p3, *p3);
}
float *f9(void)
{
float temp = 458.0039;
float *ptrf = &temp;
return ptrf;
}
float *f10(void)
{
static float temp = 458.0039;
float *ptrf = &temp;
return ptrf;
}
Obsérvese que ésta segunda versión del programa es casi idéntica a la versión anterior, las definiciones de las diez funciones siguen siendo las mismas, excepto que a la segunda versión del programa, dentro de la función principal main(), se le han agregado variables puntero a funciones:
char (*F1)(int x);
double (*F2)(int x);
float (*F3)();
void (*F4)();
float *( (*F5)() );
Obsérvese el uso de letras mayúsculas con las cuales distinguimos aquí una función fn() de su correspondiente puntero de función Fn). Obsérvese también que mientras que las diez funciones son funciones globales al haber sido declaradas y definidas fuera de la función principal main(), los punteros de función son locales al haber sido declarados dentro de main().
Tómese por ejemplo el puntero de función F2:
double (*F2)(int x);
Una vez declarado F2, podemos dar por hecho que el lugar hacia donde apunta no contiene ninguna información útil, y el puntero tiene que ser inicializado. Y es inicializado dentro de main() con la instrucción (recuérdese que escribir el nombre de una función sin los paréntesis hace que el compilador interprete al identificador como el domicilio de la función):
F2 = f2;
con la cual inicializamos el puntero a función F2 pasándole el domicilio (punto de entrada) de la función f2() que está definida como:
double f2(int x)
{
double y, z;
y = (double) x;
z = sqrt(y);
return z;
}
y con la cual se recibe como argumento un número entero, el cual con una operación de cast es promovido a un número flotante de doble precisión y, y al cual se le saca raíz cuadrada con la función de biblioteca sqrt(), misma que es regresada por la función f2(). De este modo, se invoca dentro de main() a f2() mediante el puntero de función F2, lo cual permite imprimir la raíz cuadrada de un número entero con la instrucción:
printf("El entero %d tiene raiz cuadrada %lg", i, F2(i));
después de haberle pedido previamente al usuario el número al cual se le extraerá la raíz cuadrada con la instrucción:
printf("\n\nDame un entero para darte su raiz cuadrada: ");
scanf("%d", &i);
Todos los demás punteros a funciones trabajan de la misma manera. Obsérvese el paso opuesto que se ha dado en el enunciado F2(i). Si F2 es un puntero a una función, lo lógico es que el compilador a F2() como una función en toda la extensión de la palabra.
Hablaremos ahora sobre la adjudicación dinámica de la memoria, lo cual permite la creación dinámica de variables cuando se está ejecutando un programa.
Hay dos maneras en las que un programa C puede almacenar información en la memoria RAM de una computadora. La primera manera que ya hemos estado usando en forma extensa usa variables globales y locales que son definidas mediante el lenguaje C. En el caso de las variables globales, que son declaradas al principio del programa fuera de la función principal main() y fuera de cualquier otra función, el almacenamiento requerido se mantiene fijo durante todo el transcurso del programa. En el caso de las variables locales, el almacenamiento es adjudicado del espacio disponible en la pila (stack). En ambos casos, se requiere que el programador conozca de antemano la cantidad de almacenamiento requerida para cada situación, esto con el fin de no exceder las capacidades de la máquina. Y la segunda manera en que podemos almacenar información es a través de la adjudicación dinámica de la memoria. En este método, el almacenamiento puede ser adjudicado tomando espacio del área libre de memoria que se encuentra entre el programa y su área de almacenamiento permanente para variables globales, y la pila cuando la memoria está repartida de tal modo (hay otras maneras en las cuales se puede repartir la memoria, pero usaremos esta como base). La siguiente figura nos muestra cómo aparece repartida la memoria bajo este tipo de esquema:

Se aclara en la ilustración de arriba que la memoria baja es el punto en donde se encuentra la localidad más baja de la memoria RAM (por ejemplo 0000) mientras que la memoria alta es el punto en donde se encuentra la localidad más alta de la memoria RAM (por ejemplo FFFF). Como lo indican las flechas, la pila va creciendo hacia abajo, de modo tal que la cantidad de memoria requerida estará determinada por la manera en la cual el programa C es construído. La memoria disponible para adjudicación (dinámica) es una zona de la memoria RAM que se encuentra libre y en la cual no hay nada, una zona disponible para cosas que queramos ir metiendo ya sea datos que sean parte del programa (variables globales) o datos que vayan a ser puestos en la pila,
Podemos imaginar que todo lo anterior ocurre en una máquina cuyo espacio de memoria RAM se extiende a 64 kilobytes (64K), o sea desde el domicilio 0000 hasta el domicilio FFFF. Si bien esto era mucha memoria en los tiempos en los que la memoria RAM era construída con núcleos magnéticos de ferrita en donde se almacenaban los “unos” y “ceros”, con el advenimiento de procesadores como el Intel 80286 y 80386 esto se volvió notoriamente insuficiente. Suponiendo que, gracias a una mayor capacidad de domiciliamiento del procesador CPU, es posible ir agregando más memoria RAM en bancos de hardware de 64 kilobytes cada uno, entonces podemos empezar con una computadora cuya memoria RAM tiene 128 kilobytes (128K) en total. El primer banco de RAM puede ser accesado considerado como una página, la primera página, y el segundo banco de RAM sería considerado como la segunda página. Distinguiendo la primera página como 0 y la segunda página como 1, la capacidad de domiciliamiento podría ir desde 0:0000 hasta 0:FFFF (o en representación binaria ordinaria, desde 00000 hasta 0FFFF) , y la capacidad de domiciliamiento de la segunda página podría ir desde 1:0000 hasta 1:FFFF (o en representación binaria ordinaria, desde 10000 hasta 1FFFF). Este esquema permite meter el programa en un banco de memoria, que de aquí en delante llamaremos segmento, y meter los datos en otro segmento.
El primer procesador de amplio uso en las computadoras personales caseras, el Intel 8086, tenía una capacidad de domiciliamiento de 1 megabyte. Para accesar un megabyte de RAM se requiere un esquema de domiciliamiento que use 20 bits. Sin embargo, en ese procesador no había un registro interno en el CPU cuya capacidad fuese mayor de 16 bits, lo cual implicó que el domicilio de 20 bits tuviese que ser subdividido entre dos registros del CPU, de 16 bits cada uno, con una capacidad teórica de domiciliamiento total de 32 bits. Para fines de programación, los domicilios de la memoria RAM pueden ser identificados bajo un esquema de segmento y desplazamiento (offset), y de hecho el método de domiciliamiento usado por la serie de procesadores Intel 80x86 en la segmentación de memoria de la serie x86 es conocido como el método segmento-desplazamiento. Como ya se asentó arriba, un segmento es una región de memoria RAM de 64K que debe empezar en un múltiplo par de 16. En la terminología de los procesadores 80x86, a los 16 bytes se les llamó un párrafo, y es por ello que en la literatura de aquellos tiempos a veces se encuentra el término acotamiento de párrafo (paragraph boundary) usado para referirse a estos múltiplos pares de 16 bytes. La arquitectura x86 definió cuatro segmentos: un segmento usado para el código, otro segmento usado para los datos, otro segmento usado para la pila, y un segmento extra (estos segmentos se pueden traslapar, o pueden estar separados). La localidad de cualquier byte dentro de un segmento está fijada por el desplazamiento. Poniéndolo de otra manera, el valor de un registro de segmento (ubicado en la unidad de procesamiento CPU, o sea dentro del microprocesador 8086) determina cuál es el segmento de 64K está siendo referenciado, y el valor del desplazamiento determina cuál byte, dentro de ese segmento, está siendo domiciliado. De este modo, el domicilio físico de 20 bits de cualquier byte almacenado en la computadora es la combinación del segmento y el desplazamiento.
En el lenguaje C en donde en principio, mediante el uso de los punteros, es posible dirigirse directamente a cualquier byte almacenado en la memoria, el esquema de segmentos y desplazamientos en el hardware de la memoria es lo que desde un comienzo condujo a la complejidad que requirió de varios modelos de memoria. Mientras estemos accesando únicamente domicilios dentro de un mismo segmento almacenado en un registro de segmento del procesador CPU, lo único que hay que cargar en el registro del procesador es el desplazamiento (offset) del domicilio RAM, lo cual significa que cualquier cosa referenciada usando únicamente un domicilio de 16 bits debe estar dentro del segmento actualmente cargado. A esto se le llamó domicilio cercano (near adress), y también puntero cercano (near pointer) para fines de programación en C.
Para poder accesar un domicilio que no se encuentra dentro del segmento actual, tanto el segmento como el offset del domicilio RAM deseado deben ser cargados en el registro de segmento. A esto se le llama domicilio lejano (far adress) o puntero lejano (far pointer). Un puntero lejano puede accesar cualquier domicilio dentro de un espacio en RAM de un megabyte.
Unicamente es necesario cargar en el registro de segmento del CPU el offset de 16 bits para accesar memoria dentro del segmento actual. Sin embargo, si se quiere accesar memoria RAM que se encuentre fuera de dicho segmento, si se quiere “salir fuera” del segmento, entonces tanto el segmento como el desplazamiento tienen que ser cargados con sus valores respectivos en el registro de domiciliamiento del CPU. Y he aquí la consecuencia: puesto que se toma el doble de tiempo cargar dos registros de 16 bits cada uno (el registro del segmento, y el registro del desplazamiento) que cargar un solo registro, se toma mayor cantidad de tiempo cargar un puntero lejano que cargar un puntero cercano. Por lo tanto, los programas se ejecutan con mucha mayor lentitud usando punteros lejanos que usando punteros cercanos, esto además de que el uso de punteros lejanos ocasiona que el programa sea más grande. Sin embargo, los punteros lejanos son lo que permite tener programas de mayor extensión o manejar una mayor cantidad de datos.
Los primeros compiladores C elaborados para la familia de procesadores Intel 80x86 podían compilar un programa de seis maneras diferentes, y cada manera organiza de modo distinto la memoria RAM de la computadora cuando se usa uno de los modelos de memoria Intel. Los seis modelos son llamados tiny (pequeñito), small (pequeño), medium (mediano), compact (compacto), large (grande) y huge (grandísimo).
En el modelo de memoria tiny se compila un programa C de modo tal que todos los registros de segmento del CPU siempre tienen el mismo valor y todo el domiciliamiento es efectuando usando 16 bits (punteros cercanos). Esto significa que todo el código, todos los datos, y la pila son puestos en el mismo segmento de 64K. Este modelo fue usado para producir los archivos ejecutables conocidos como COM. El modelo tiny permite obtener las velocidades de ejecución más rápidas.
El modelo de memoria small fue desde un principio el modelo predeterminado usado por C para llevar a cabo la compilación de programas fuente, usado para una gran variedad de tareas. Aunque el domiciliamiento es hecho usando únicamente el offset de 16 bits, el segmento adjudicado al código del programa es puesto separadamente de los segmentos de datos, pila y segmento extra. Esto significa que el tamaño total de un programa compilado de esta manera reparte el código y los datos en los 128K de memoria RAM utilizada. Puesto que el modelo small usa únicamente punteros cercanos, la velocidad de ejecución es tan buena como para el modelo tiny, pero el programa puede ser el doble de grande (más o menos).
El modelo de memoria medium fue reservado para programas grandes en donde el código excede la restricción de un segmento para el modelo small. Aquí el código puede usar segmentos múltiples y requiere del uso de punteros de 20 bits (punteros far), pero la pila, los datos y el segmento extra son puestos cada uno en sus propios segmentos y usan domiciliamiento de 16 bits (punteros cercanos). Los programas se ejecutan con mayor lentitud en lo que respecta al llamado de funciones, pero las referencias a los datos son tan grandes como el modelo small.
El modelo compact es el complemento del modelo medium. Aquí el código del programa es restringido a un segmento pero los datos pueden ser puestos en varios segmentos. Esto significa que todos los accesos a los datos requieren del uso de domiciliamiento de 20 bits (punteros lejanos), pero el código usa domiciliamiento de 16 bits (punteros cercanos). Este tipo de modelo es el modelo ideal para programas que requieren grandes cantidades de datos pero relativamente poco código; el programa se ejecuta tan rápido como el modelo small excepto cuando hay que manipular datos, y entonces se ejecutará con mayor lentitud.
El modelo large permite que tanto el código como los datos usen varios segmentos de memoria; sin embargo el mayor artículo de datos, como un array, está limitado a 64K. Es el modelo a usar cuando se tiene mucho código y muchos datos, pero como es de esperarse los programas se ejecutan con mucha mayor lentitud que los modelos de memoria descritos previamente.
El modelo huge es lo mismo que el modelo large excepto que los artículos individuales de datos pueden exceder 64K, lo cual ocasiona una degradación mayor en la velocidad de ejecución del programa.
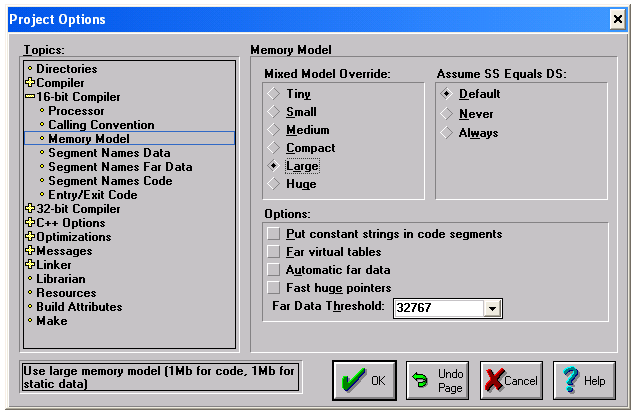
En un entorno IDE como Borland C++ el programador es quien debe seleccionar el modelo de memoria bajo el cual será compilado su proyecto en lenguaje C, mediante una ventana como la siguiente (en la subventana Mixed Model Override podemos ver seleccionado el modelo large):
Al ir evolucionando la tecnología, los modelos de memoria se han ido superando requiriéndose la introducción de nuevos compiladores C capaces de poder manejar las nuevas arquitecturas de procesadores. En el 2014 se tenía ya el lenguaje C# introducido por Microsoft para sacarle provecho a las arquitecturas capaces de usar memorias RAM en el orden de los gigabytes.
En la década de los ochenta, los programadores que estaban familiarizados con procesadores de domiciliamiento lineal (en los cuales simplemente se especifica el domicilio en la memoria RAM sin tener que entrar en detalles de segmentos y desplazamientos) encontraron el esquema usado en los procesadores Intel 80x86 exasperante, y algunas de las soluciones variaron de ignorar el problema a utilizar siempre el modelo más grande disponible de memoria y pretender que estaban trabajando en una máquina con un espacio de memoria linear, para ellos lo ideal hubiera sido que, desde un principio, para el hardware se hubieran tenido disponibles procesadores capaces de domiciliar en forma lineal una gran memoria RAM de unos 4 gigabytes de capacidad, sin tener que usar estos esquemas de segmento/offset que se usaron desde un principio. Y de hecho, el procesador Intel 80386 usaba ya un espacio linear de domiciliamiento, aunque también ofrecía la capacidad para poder ejecutar programas en un esquema de memoria segmentada haciendo posible la compatibilidad hacia atrás que evitaba lo que de otra manera hubiera sido la obsolescencia forzada de muchos programas comerciales elaborados en C para esquemas de memoria segmentada, aunque al costo de introducir complejidades adicionales en el sistema operativo tales como el tener que implementar lo que se conoce como el modo protegido. Pero, viendo hacia atrás, tales complicaciones son imposibles de anticipar, como igualmente es imposible anticipar hoy los brincos que dará la tecnología en el futuro, y hay que estar preparados siempre para enfrentrar las nuevas posibilidades, con la tranquilidad y seguridad que para ellas se desarrollarán nuevos compiladores y entornos IDE de programas escritos en lenguaje C.
Con lo anterior en mente, podemos volver a considerar el tema de la adjudicación dinámica de la memoria libre, en donde en vez de tener una porción fija de la memoria RAM reservada exclusivamente para los datos y otra porción fija de la memoria RAM reservada para la pila, el espacio reservado para la pila y/o los datos puede crecer a expensas del espacio reservado para la memoria libre así como disminuír.
Es común encontrar en muchas bibliotecas C de una gran variedad de sistemas dos funciones usadas para la adjudicación dinámica de la memoria, la función malloc() (memory allocate) y free() (liberar memoria). Estas dos funciones trabajan en forma conjunta, la primera adjudica memoria, y la segunda libera memoria que haya sido adjudicada. Cada vez que se hace una requisición a la función malloc(), se adjudica una porción de la memoria libre, mientras que cada vez que se hace una invocación a la segunda función se le regresa al sistema memoria que había diso adjudicada. Los prototipos de estas dos funciones es encontrado generalmente en un archivo de cabecera como STDLIB.H, aunque esto puede variar en algunos sistemas.
La función malloc() tiene el siguiente prototipo:
void *malloc(unsigned número_de_bytes);
Como puede verse en el prototipo, la función regresa un puntero nulo (de tipo void). Esto significa que se le puede asignar a cualquier tipo de puntero (precisamente es para cosas como la adjudicación dinámica de la memoria fueron diseñados los punteros nulos). Después de una invocación exitosa (lo cual presupone que hay suficiente memoria RAM libre disponible para atender la petición), malloc() regresará un puntero al primer byte de la región de la memoria adjudicada del “montículo” (la zona de la memoria libre disponible para ser adjudicada). Si no hay suficiente memoria libre para ser adjudicada, ocurre un error de adjudicación y malloc() regresa un nulo.
La función free() hace lo inverso de malloc(), regresándole al sistema memoria que haya sido adjudicada previamente. Una vez que se ha liberado memoria RAM, ésta puede ser usada para otros fines con una llamada subsecuente a malloc(). Esta función tiene el siguiente prototipo:
void free(void *p);
En este punto se formula una advertencia que hay que tener siempre presente. Jamás se debe invocar la función free() usando un argumento que no sea válido, ya que en caso de hacerse tal cosa la lista de lo que hay libre será destruída.
A modo de ejemplo, el siguiente programa adjudica suficiente espacio en la memoria RAM para almacenar dinámicamente 20 enteros, imprime sus valores, y una vez hecho le regresa al sistema la memoria RAM que fue adjudicada (el programa usa la función de biblioteca sizeof() que determina en el sistema de cómputo que se está usando el tamaño en bytes del tipo int, esto para permitir que el programa sea portátil a varios tipos de máquina en donde int puede ser especificado con 4 bytes, con 8 bytes, o tal vez más, dependiendo de los avances tecnológicos que se vayan dando en la microminiaturización):
#include <stdio.h>
#include <stdlib.h>
main(void)
{
int *p, t;
p = malloc(20*sizeof(int));
if(!p) /* asegurar que p es un puntero valido */
printf("fuera de memoria\n");
else {
for(t=0; t<20; ++t) *(p+t) = t;
for(t=0; t<20; ++t) printf("%d ", *(p+t));
free(p); /* liberar la memoria adjudicada */
}
return 0;
}
Como se pone en práctica en el ejemplo anterior, antes de usar el puntero regresado por malloc() se asegura primero el éxito de la requisición de adjudicación probando este valor en contra de cero con la instrucción if(!p).
La adjudicación dinámica de la memoria resulta extremadamente útil cuando se desconoce de antemano con cuántos datos se estará trabajando, y un ejemplo de ello es una lista de inventario en la cual se irán agregando artículos a la lista no sabiendo cuántos artículos serán agregados cuando la lista se haya completado. Los ejemplos de adjudicación dinámica de la memoria suelen ser relativamente largos y complejos, pero podemos darnos una idea de su uso en el siguiente programa usado para calcular el promedio aritmético de una cantidad arbitraria de enteros. El programa el pregunta al usuario cuántos son los números que serán promediados. Una vez que el usuario especifica la cantidad, el programa adjudica dinámicamente un array de enteros lo suficientemente grande para contenerlos, obtiene el promedio aritmético, y finalmente libera el array y con ello la memoria que había sido adjudicada:
#include <stdlib.h>
#include <stdio.h>
main(void)
{
int *p;
int num, i, prom;
printf("dame la cantidad de enteros a promediar: ");
scanf("%d", &num);
/* adjudicacion dinamica de espacio en la memoria RAM */
if((p = malloc(sizeof(int)*num))==NULL) {
printf("allocation error");
exit(1);
}
for(i=0; i<num; i++) {
printf("%d: ", i+1);
scanf("%d", &p[i]);
}
prom = 0;
for(i=0; i<num; i++) prom = prom + p[i];
printf("el promedio es: %d", prom/num);
free(p); /* liberacion de la memoria RAM adjudicada */
return 0;
}