Cabe agregar que actualmente el uso de la palabra “objeto” para describir un módulo intermedio que contiene código en lenguaje de máquina es desafortunado en estos tiempos modernos en los que se habla de la programación orientada a objetos. En un contexto algo añejo, la palabra “objeto” empezó a ser utilizada mucho antes de que cualquiera hubiera pensado en algo tan refinado como la programación orientada a objetos. Al hablar sobre procesos de compilación, la palabra “objeto” es usada en la misma connotación en la que se habla de una “meta”, mientras que cuando la palabra es usada en el ámbito de la programación orientada a objetos su significado es algo completamente diferente, algo así como “una cosa con fronteras bien definidas”.
El enlazador combina una lista de módulos objeto produciendo un programa ejecutable que puede ser cargado y corrido por el sistema operativo de la máquina hacia la cual está dirigido. Cuando una función C en un módulo objeto hace una referencia a otra función o variable en otro módulo objeto, el enlazador se encarga de resolver las diferencias y combinarlo todo de manera adecuada. El enlazador es el que se encarga de llevar a cabo una búsqueda a través de archivos especiales llamados bibliotecas, las cuales contienen una colección de módulos objeto en un solo archivo.
Para poder romper un programa C extenso en varios módulos manejables de menor tamaño, recurrimos a la palabra clave reservada extern usada para declarar variables y funciones que pueden estar puestas en alguno de varios módulos. La palabra extern le dice al compilador que cierta porción de dato o función existe en algún lado aunque el compilador aún no haya visto tal cosa en el archivo que está siendo compilado, y puede existir en algún otro archivo (o sea, es externa al archivo bajo consideración) o puede encontrarse aún más abajo en el archivo actual que está siendo compilado. A continuación tenemos un programa que ha sido subdividido en dos módulos, el Módulo 1 y el Módulo 2. Obsérvese que en el Módulo 1 hemos declarado tanto a la variable x3 como a la función salida() como extern, y en el Módulo 2 hemos declarado a las variables x1 y b como extern:

En el Módulo 1, cuando el compilador encuentra la declaración extern int x3 sabe que la definición para x3 se encontrará en algún lado como una variable global, y esta definición puede estar en el archivo actual, o posteriormente, en un archivo separado. Con esto se evita que el compilador genere un mensaje de error al terminar el proceso de compilación del primer archivo, quedando pendiente localizar la definición de x3 al llevarse a cabo la compilación de los demás archivos, en este caso el Módulo 2. Cuando el compilador encuentra la definición de x3 en el Módulo 2, sabe que ha encontrado el mismo x3 declarado en el Módulo 1, resolviéndose lo que había quedado pendiente. Por otro lado, aunque en el Módulo 2 no aparece la definición de x1, puesto que es declarada en dicho módulo como extern el compilador busca la definición de dicha variable hasta encontrarla en el Módulo 1. Obsérvese que x3 es conocida a todas las funciones de todos los archivos (módulos) de que conste el programa, aunque no sea usada para nada por ninguna función. Esto permite incluír posteriormente a dicha variable en caso de que una expansión del proyecto así lo requiera, haciendo al proyecto extensible.
Inspeccionando el código del Módulo 1, vemos que los enteros x1 y x2 son declarados como variables globales al estar puestos fuera de main(), y por lo tanto son nombres públicos. Lo mismo ocurre con los flotantes a y b en dicho módulo, al igual que la variable Factor. Por otro lado, las variables estáticas no son accesibles fuera del archivo Módulo 1, y por lo tanto no son nombres públicos. En lo que toca a la función salida(), al ser declarada como una función extern es un nombre público. Por otro lado, las variables x4 y x5, por haber sido declaradas dentro de main(), no son nombres públicos. Lo mismo puede decirse de la variable m declarada dentro de la función peso(), tampoco es un nombre público.
En lo que toca al Módulo 2, las variables x1 y b son nombres públicos, y aunque no son inicializadas en el Módulo 2 su inicialización es tomada del Módulo 1 al haber sido declarado ambas como extern.
El proyecto que se acaba de proporcionar consta únicamente de dos módulos. Pero un proyecto puede constar de muchos más módulos, desde luego. En la entrada anterior vimos un programa C que definía diez funciones distintas además de la función principal main(). Tomaremos ese programa y lo repartiremos entre once archivos distintos, siendo el primero el programa que contendrá a la función principal main() y que será guardado en el disco duro bajo el nombre MAIN.C (podemos asignarle cualquier otro nombre si así lo deseamos):
-- Archivo MAIN.C --
#include "stdio.h"
#include "math.h"
/* DECLARACION DE PROTOTIPOS DE FUNCIONES EXTERNAS REQUERIDAS POR EL */
/* PROGRAMA, COMPILADAS POR SEPARADO A ARCHIVOS .OBJ Y ENLAZADAS POR */
/* EL LINKER PARA LA CREACION DE UN PROGRAMA INTEGRAL */
extern char f1(int x);
extern double f2(int x);
extern float f3(int x, int y), f4(int x);
extern void f5(char x[80]);
extern void f6(char x[80]);
extern void f7(char x[80]);
extern void f8(char *p1, int *p2, float *p3);
extern float *f9(void);
extern float *f10(void);
void main(void)
{
int i, j, k, q, r, s, t;
float x, y, z;
char ch, frase[80], *ptr, str[] = "Programar en c es divertido";
float *X;
printf("\nDame un entero positivo para darte el caracter ASCII: ");
scanf("%d", &i);
ch = f1(i);
printf("Al entero %d le corresponde el caracter %c", i, ch);
printf("\n\nDame un entero para darte su raiz cuadrada: ");
scanf("%d", &i);
printf("El entero %d tiene raiz cuadrada %lg", i, f2(i));
printf("\n\nDame un numero entero pitagorico: ");
scanf("%d", &i);
printf("Dame otro numero entero pitagorico: ");
scanf("%d", &j);
z = f3(i, j);
printf("El modulo complejo de %d y %d es %f", i, j, z);
printf("\n\nDame un entero mayor que cero: ");
scanf("%d", &k);
x = f4(k);
printf("El logaritmo base 10 de %d es %f\n", k, x);
f5(str);
f6(str);
f7(str);
ch = getch();
ch = 'U';
i = -3067;
x = 45.0349;
f8(&ch, &i, &x);
X = f9();
printf("\n\nEl valor *X almacenado bajo el puntero X es %f", *X);
X = f10();
printf("\nEl valor *X almacenado bajo el puntero X es %f", *X);
printf("\n\nLa funcion printf() con los tres argumentos:\n");
i = printf("%c, %d, %f", 'M', 37, 65.38);
printf("\nregresa el valor %d, la cantidad de caracteres impresa", i);
printf("\n\nLa funcion scanf() pidiendo cuatro argumentos enteros:\n");
i = scanf("%d %d %d %d", &q, &r, &s, &t);
printf("regresa el valor %d, la cantidad de argumentos leida", i);
printf("\n\nEl domicilio de la funcion f1() es %p", f1);
printf("\nEl domicilio de la funcion f2() es %p", f2);
printf("\nEl domicilio de la funcion f5() es %p", f5);
flushall();
printf("\n\nDame una frase corta: ");
gets(frase);
printf("La frase es \"%s\"", frase);
printf("\nDame otra frase corta: ");
ptr = gets(frase);
printf("La frase es \"%s\"", ptr);
}
Lo más importante es que las funciones definidas por el programador que serán invocadas por main() no aparecen definidas en el anterior archivo de texto, simplemente son declaradas, y son declaradas con la palabra reservada extern, la cual le dice al compilador que las definiciones deben estar en algún otro lado, en algún otro archivo. Y este será un proyecto conformado por once archivos en total, al almacenar la definición de cada función en un archivo separado.
A continuación, guardaremos en un archivo de texto titulado F1.C la definición de la función f1():
-- Archivo F1.C --
#include "ctype.h"
/* Es necesario incluir DENTRO del archivo que contiene a la */
/* funcion f1() el archivo de cabecera CTYPE.H para la */
/* definicion de la funcion de biblioteca toascii() */
char f1(int x) /* Definicion de la funcion f1() */
{
char ch;
ch = toascii(x);
return ch;
}
Del mismo modo, podemos ir guardando en archivos separados e independientes cada una de las demás funciones, con lo cual el proyecto constará de once archivos en total. Obsérvese que a cada archivo se le va poniendo la extensión .C, aunque los requerimientos relacionados con la extensión anexada al nombre de cada archivo pueden variar de sistema a sistema:
-- Archivo F2.C --
\#include "math.h"
/* Es necesario incluir DENTRO del archivo que contiene a la */
/* funcion f2() el archivo de cabecera MATH.H que da acceso */
/* a la definicion de la funcion de biblioteca sqrt() */
double f2(int x) /* Definicion de la funcion f2() */
{
double y, z;
y = (double) x; /* Promovemos el parametro x de int a doble */
z = sqrt(y);
return z;
}
-- Archivo F3.C --
#include "math.h"
/* Es necesario incluir DENTRO del archivo que contiene a la */
/* funcion f3() el archivo de cabecera MATH.H que da acceso */
/* a la definicion de la funcion de biblioteca sqrt() */
float f3(int x, int y) /* Definicion de la funcion f3() */
{
float z;
z = sqrt( (float) ( (x*x) + (y*y) ) );
return z;
}
-- Archivo F4.C --
#include "math.h"
/* Es necesario incluir DENTRO del archivo que contiene a la */
/* funcion f4() el archivo de cabecera MATH.H que da acceso */
/* a la definicion de la funcion de biblioteca log() */
float f4(int x) /* Definicion de la funcion f4() */
{
double y;
y = log10( (float) x);
return y;
}
-- Archivo F5.C --
#include "stdio.h"
/* Este archivo de cabecera es requerido para que la funcion f5() */
/* pueda tener acceso a la funcion printf() cuyo prototipo aparece */
/* en dicho archivo de cabecera */
void f5(char str[80]) /* Definicion de la funcion f5() */
{
printf("\nf5(): %s", str);
}
-- Archivo F6.C --
#include "stdio.h"
/* Este archivo de cabecera es requerido para que la funcion f5() */
/* pueda tener acceso a la funcion printf() cuyo prototipo aparece */
/* en dicho archivo de cabecera */
void f6(char str[])
{
printf("\nf6(): %s", str); /* Definicion de la funcion f6() */
}
-- Archivo F7.C --
#include "stdio.h"
/* Este archivo de cabecera es requerido para que la funcion f5() */
/* pueda tener acceso a la funcion printf() cuyo prototipo aparece */
/* en dicho archivo de cabecera */
void f7(char *str) /* Definicion de la funcion f7() */
{
printf("\nf7(): %s", str);
}
-- Archivo F8.C --
#include "stdio.h"
/* Este archivo de cabecera es requerido para que la funcion f5() */
/* pueda tener acceso a la funcion printf() cuyo prototipo aparece */
/* en dicho archivo de cabecera */
void f8(char *p1, int *p2, float *p3)
{
printf("\n\nEl valor *p1 en el domicilio\n");
printf("%p dentro de f8() es %c",p1, *p1);
printf("\n\nEl valor *p2 en el domicilio\n");
printf("%p dentro de f8() es %d", p2, *p2);
printf("\n\nEl valor *p3 en el domicilio\n");
printf("%p dentro de f8() es %f", p3, *p3);
}
-- Archivo F9.C --
float *f9(void) /* Definicion de la funcion f9() */
{
float temp = 458.0039;
float *ptrf = &temp;
return ptrf;
}
-- Archivo F10.C --
float *f10(void) /* Definicion de la funcion f10() */
{
static float temp = 458.0039;
float *ptrf = &temp;
return ptrf;
}
Al final, tendremos diez archivos de texto diferentes, todos ellos con la extensión .C (la extensión también puede ser .CPP dependiendo del compilador o del entorno IDE, o tal vez ni siquiera se requiera usar una extensión de archivo) que indica que se trata de porciones de código en lenguaje C que en conjunto forman parte de un programa fuente.
En el siguiente paso, el proceso de construcción involucra la compilación individual e independiente de cada archivo no a un programa ejecutable, sino a un archivo intermedio conocido como archivo objeto. Una vez que todos los archivos han sido convertidos a archivos objeto, el paso final consiste en enlazarlos y unirlos en un programa ejecutable, para lo cual se requiere un programa que los pueda enlazar, el linker o programa enlazador. De hecho, aún cuando todo un programa C conste de un solo archivo fuente del cual se obtendrá un archivo ejecutable, el proceso de compilación de cualquier manera involucra la creación automática de un archivo intermedio (archivo objeto) así como la transferencia automática del archivo objeto al enlazador (este último paso no lo “vemos” en muchos entornos integrados de desarrollo a menos de que exhiban en algún lado de la ventana la etapa que se está llevando a cabo).
Así pues, podemos bosquejar el proceso de construcción del proyecto de la siguiente manera:
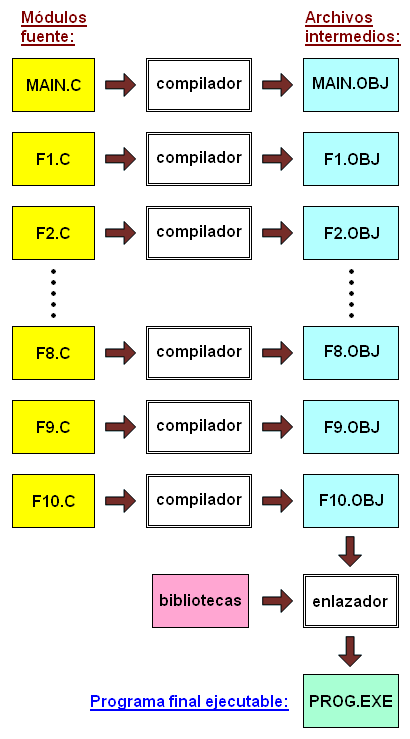
Las operaciones específicas que se tengan que llevar a cabo dependerán del paquete de software de compilación C que se esté utilizando así como del tipo de ventana en que se esté trabajando, ya sea una ventana de líneas de comandos o la interfaz visual de un entorno integrado de desarrollo IDE. En los viejos sistemas operativos UNIX que marcaron la pauta a seguir en los sistemas operativos con ventanas basadas en líneas de comandos, el compilador UNIX C era invocado con cc (abreviatura de C Compiler), y para compilar un programa elaborado en código fuente con un nombre como armando.c se escribía la siguiente línea:
cc armando.c
y se oprime en el teclado la tecla de entrada [Enter] con lo cual el programa es compilado hacia un archivo ejecutable. Después de algunos segundos, y en caso de no haber errores en el programa fuente (en caso de haberlos, UNIX pone en la pantalla una serie de advertencias y mensajes de error), UNIX produce un nuevo archivo llamado a.out, el archivo ejecutable que contiene la traducción (o compilación) del programa fuente. Para ejecutar el programa ya compilado, se escribe simplemente:
a.out
y se oprime en el teclado la tecla de entrada [Enter] con lo cual se ejecuta el programa.
La metodología usada por UNIX es más directa que la metodología usada por un paquete como Microsoft C para el sistema operativo PC-DOS 3.1 en las máquinas tipo IBM PC, ya que primero había que efectuar la siguiente operación con el archivo fuente (el compilador Microsoft C interpreta armando como el archivo fuente armando.c):
msc armando;
Este primer paso produce un archivo llamado armando.obj que contiene el código objeto (código en lenguaje de máquina) para el programa. El siguiente paso consiste en escribir:
link armando;
con lo cual se invoca el enlazador (linker), lo cual produce un nuevo archivo titulado armando.exe, el archivo ejecutable. Interesantemente, link era un programa que venía ya previamente incluído con el sistema operativo IBM DOS, pese a que ninguna de esas computadoras personales caseras era vendida con un compilador C incluído en ellas.
Para compilar en UNIX programas C con dos o más archivos tales como archivo1.c y archivo2.c, el comando de línea usado es:
cc archivo1.c archivo2.c
De nueva cuenta, esto produce en UNIX un archivo llamado a.out, el archivo ejecutable (el nombre siempre era a.out). Pero además se generaban dos archivos objeto llamados archivo1.obj y archivo2.obj. De este modo, si tiempo después se cambiaba el archivo fuente archivo1.c dejando intacto el archivo archivo2.c se podía compilar el primero combinándolo con la versión en código objeto del segundo archivo mediante el comando:
cc archivo1.c archivo2.o
En el paquete Microsoft C, se compilan por separado archivo1.c y archivo2.c produciendo dos archivos de código objeto llamados archivo1.obj y archivo2.obj, usando el linker para combinarlos hacia un programa ejecutable:
link archivo1 archivo2
Todas las operaciones mostradas se pueden hacer desde una ventana de líneas de comandos, y de hecho hay programadores experimentados que se sienten cómodos trabajando de este modo. Sin embargo, la práctica moderna consiste en recurrir a entornos integrados de desarrollo IDE en los cuales la mayoría de las operaciones se llevan a cabo usando el Mouse en lugar de hacerlo todo a través del teclado, y es en esto en lo que queremos enfocar nuestra atención. A estas alturas lo más conveniente por razones didácticas es apoyarnos en un ejemplo específico que puede servir como ilustración. Usaremos los paquetes conocidos como Turbo C y Borland C++, los cuales popularizaron en forma masiva el aspecto visual que encontramos en la mayoría de los entornos integrados de desarrollo IDE para el lenguaje C usados desde cuando aparecieron las primeras computadoras personales caseras.
Al abrir un entorno como Borland C++ se presenta una ventana principal de trabajo en la cual lo único que realmente destaca es una línea de menú que contiene las siguientes opciones:
File Edit Search View Project Debug Tool Options Window Help
La gran mayoría de los entornos integrados de desarrollo modernos en casi cualquier lenguaje de programación ofrecen este tipo de opciones ya sea en una línea de menú o en un tablero de selección de opciones. Para construír un proyecto la opción que procuramos en la línea de menú es la que tiene un nombre como “Project”. En un entorno como Turbo C esto abre una lista de opciones como la siguiente:
| New project... Open project... Close project |
| Add item... Delete item Local options Include files |
Con la sub-opción “New project...” se abre una ventana de opciones para la construcción del nuevo proyecto, mientras que con la sub-opción “Open project” se abre una ventana para seleccionar un proyecto previo existente en el disco duro de la computadora. La sub-opción “Close project” aparece apagada a menos de que se tenga abierto un proyecto. Del mismo modo, las demás sub-opciones solo se activarán cuando se está trabajando sobre un proyecto abierto.
En Borland C++, escogiendo la sub-opción “New project...” para abrir un proyecto nuevo, aparece algo como lo siguiente:

En la caja de texto “Project Path and Name:” escogemos la ruta (al estilo DOS) que indica el lugar exacto (carpeta o sub-carpeta) en donde pondremos el proyecto, y allí mismo le podemos dar al proyecto cualquier nombre, por ejemplo “proye001.ide” usándose la extensión de archivo “ide” para hacerlo localizable por el entorno IDE. En la caja de texto “Platform” escogemos el sistema operativo (plataforma) para la cual será compilado el archivo ejecutable, habiendo (en ese IDE) cuatro plataformas disponibles:
Windows 3.x (16 bits)
Win32 (32 bits)
DOS (Standard)
DOS (Overlay)
Al dar la aceptación a todo el conjunto de las opciones seleccionadas, aparece en la parte inferior de la ventana de trabajo otra ventana en la cual se muestran dos líneas, una para el archivo ejecutable y la otra para el archivo fuente que llevará la extensión “.CPP”:

Puesto que en un proyecto completamente nuevo recién abierto no hay archivo ejecutable alguno, la única opción es disponible es la línea que corresponde al archivo fuente (segunda línea). Haciendo doble-clic con el Mouse en la segunda línea, aparece una ventana en donde empezamos a meter el código fuente del programa:

Por simple copiado y empastado, podemos meter el código fuente del archivo MAIN.C del programa dado arriba:

Y de hecho, si tenemos todo (o sea la función principal main() y las diez funciones adicionales que usa el programa) en un solo archivo fuente, podemos proceder a compilar a un archivo ejecutable.
Con la sub-opción “New” de la opción “File” de la línea de menú, podemos crear el archivo correspondiente para la función f1() dándole el nombre F1.CPP, haciendo lo mismo para las demás funciones, hasta que tenemos un proyecto con once archivos listo para ser compilado a un archivo ejecutable. Una vez que hemos terminado con un proyecto, debemos cerrar el archivo del proyecto con la opción “Close project”.
Cuando se ha logrado una compilación exitosa de un proyecto que consta de varios archivos separados, hay entornos IDE que hacen un acopio de estadísticas que le permiten al programador inspeccionar el panorama grande. En el IDE Turbo C, aparece una ventana como la siguiente (en este entorno, la extensión usada para los archivos en código fuente C es “.CPP” en lugar de “.C”, de modo tal que el archivo fuente para la función f1() será designado F1.CPP, y así sucesivamente):
| File Name | Location | Lines | Code | Data |
| F1.CPP | 17 | 16 | 0 | |
| F2.CPP | 16 | 53 | 0 | |
| F3.CPP | 13 | 58 | 0 | |
| F4.CPP | 13 | 45 | 0 | |
| F5.CPP | 13 | 17 | 10 | |
| F6.CPP | 14 | 17 | 10 | |
| F7.CPP | 16 | 17 | 10 | |
| F8.CPP | 13 | 71 | 163 | |
| F9.CPP | 12 | 32 | 4 | |
| F10.CPP | 19 | 14 | 4 | |
| MAIN.CPP | 139 | 609 | 960 |
Las estadísticas, usando como ejemplo las que corresponden al archivo F6.CPP, nos dicen que el código fuente consta de 14 líneas de texto (renglones), y que el archivo objeto que corresponde al archivo en C contiene 17 bytes en código ejecutable (lenguaje de máquina binario) y 10 bytes de datos, o sea 27 bytes en total. En proyectos extensos y complejos, este tipo de información puede ser útil para seleccionar, por ejemplo, el modelo de memoria a usar, o los lugares en donde se requiere de código más eficiente que consuma menos instrucciones en lenguaje de máquina. La columna “Location” (mostrada vacía) contiene la ruta (path) de la carpeta y lugar en la memoria en donde está puesto el archivo fuente en cada caso.
De este modo, el entorno IDE acelera el proceso de construcción de un programa ejecutable que pueda contener varias miles de líneas de código.
Sin embargo, no hay que perder de vista el hecho de que un entorno integrado de desarrollo IDE para un lenguaje de programación como C en realidad no es más que una “concha” (shell) que nos evita el tener que escribir a mano todo lo que se tiene que estar escribiendo cuando se utiliza una ventana de líneas de comandos. Al final de cuentas, ambos métodos tienen que recurrir necesariamente al mismo compilador o al mismo linker, la única diferencia estriba en que el método visual con el IDE usando el Mouse es más cómodo y más rápido que el tener que estar escribiendo comandos de línea que tienen que ser memorizados, pero el resultado final sigue siendo el mismo.
Desde los tiempos de UNIX, los entornos integrados de desarrollo han incorporado varias utilierías que resultan útiles cuando se está trabajando en un proyecto grande, las cuales nos proporcionan otras maneras de poder llegar a nuestra meta. Una de tales utilerías nos permite crear nuestros propios repertorios de funciones, funciones ya compiladas a archivos objeto pero agrupadas dentro de un mismo archivo. Después de todo, esto es lo mismo que hace C, agrupando en bibliotecas estándard funciones frecuentemente usadas como las que se usan para entrada/salida como printf(), scanf(), etc.
Al crear nuestras propias funciones en C (por ejemplo unas funciones matemáticas conteniendo algoritmos para el cálculo de funciones de Bessel, y otras para el cálculo de funciones Gaussianas normales), podemos convertirlas a módulos objeto y ponerlas todas juntas en un mismo archivo, combinándolas en una biblioteca. Para crear una biblioteca que ponga en un mismo sitio aquellos módulos usados con mayor frecuencia se requiere de un programa especial llamado el bibliotecario (librarian). Muchos paquetes de programación incluyen un bibliotecario que administra grupos de módulos objeto; y cada bibliotecario trae consigo sus propios comandos, pero la idea general es ésta: si el programador quiere crear una biblioteca, se redacta primero un archivo de cabecera que contenga todos los prototipos de función para todas las funciones en nuestra biblioteca, poniendo este archivo de cabecera en algún lugar en donde pueda ser encontrado por el preprocesador C, ya sea en el directorio (carpeta) local en donde pueda ser encontrado con algo como (obsérvese el uso de las comillas dobles):
#include "cabecera.h"
o en el directorio de los archivos INCLUDE en donde pueda ser encontrado con algo como (obsérvese el uso de los paréntesis angulados):
#include <cabecera.h>
Hecho lo anterior, tomamos todos los módulos objeto (o sea, cada una de las funciones ya compiladas a módulos objeto) y se los entregamos juntos al bibliotecario con un nombre de nuestra elección para identificar la biblioteca terminada ya (muchos de los bibliotecarios asignan una extensión común como .LIB al nombre seleccionado por el programador para su biblioteca). Tomando como ejemplo las diez funciones del proyecto dado arriba, suponiendo que tenemos ya F1.OBJ, F2.OBJ, etcétera, entonces el proceso de compactación de las diez funciones hacia una biblioteca llamada FUNCS.LIB se puede bosquejar de la siguiente manera:

Una vez construida la biblioteca, se le pone en el mismo lugar (carpeta, directorio) en donde residen las otras bibliotecas y en donde pueda encontrarla el enlazador. Al usar una biblioteca de nuestra propia creación en la compilación de algún programa, tenemos que añadir algo a la línea de comandos o al entorno IDE para decirle al enlazador en dónde puede encontrar la biblioteca para hallar el código objeto de las funciones que estamos invocando en nuestro programa principal. El proceso de búsqueda emprendido por el enlazador es el mismo que se lleva a cabo cuando usamos alguna función predefinida en C como la función printf() para obtener salida formateada; al encontrarse al principio del programa una línea como:
#include <misfuncs.h>
el preprocesador C busca las definiciones de prototipos de funciones (así como macros y expansiones de macros al igual que procedimientos de compilación condicional) en el archivo de cabecera MISFUNCS.H (un archivo de texto) que debe estar en algún directorio en el disco duro en una carpeta con un nombre significativo como INCLUDE, y tras esto el enlazador busca el código objeto que corresponde a la función o funciones que se están buscando (por ejemplo tabla() o vector()) en otro directorio que debe estar puesto al mismo nivel que la carpeta INCLUDE y que puede tener un nombre como LIB (o TLIB, o MSLIB, o MacLIB, o algo parecido), y una vez que ha encontrado la biblioteca que contiene el módulo objeto que corresponde a la función buscada (tabla(), vector(), etcétera) el enlazador entra en acción sacando dicho módulo objeto de la biblioteca y enlazándolo al programa principal para terminar de producir el archivo final ejecutable.
El programador experimentado que no necesita de un entorno de desarrollo IDE puede crear sus propias bibliotecas “a la antigüita” en una ventana de líneas de comandos; si el sistema operativo que se usa no cuenta con una, casi siempre es posible obtener un programa ejecutable que produzca una ventana tal en la pantalla de la computadora. Puesto que cada bibliotecario en cada paquete (o entorno) de compilación C tiene su propia designación y sus propias convenciones, y en esto no hay acuerdo universal o al menos semi-universal en la terminología, no es posible proporcionar un método general aplicable a todos los casos. Pero se puede mencionar un ejemplo sencillo tomado del paquete Turbo C cuyo bibliotecario era TLIB (en realidad un archivo con el nombre TLIB.EXE pero para el cual basta invocarlo como TLIB sin la extensión puesto que se trata de un programa ejecutable invocable desde la línea de comandos) con la sintaxis:
TLIB Biblioteca [Operaciones] [,Listado]
en donde Biblioteca es el nombre dado por el programador a la biblioteca que está creando, Operaciones determina lo que hará el bibliotecario con lo que se le está presentando, y Listado produce una impresión que muestra los contenidos de la biblioteca. Puesto que muchos paquetes de compilación C tienen cosas parecidas al TLIB de Turbo C que a su vez se inspiró en UNIX, vale la pena repasar algunos detalles del mismo. Las Operaciones disponibles en TLIB son las siguientes:
| Operación | Significado | Propósito |
| + | Agregar | El bibliotecario agrega el archivo designado a la biblioteca. Si el módulo que está siendo agregado ya existe, se da un mensaje y no se agrega el modulo nuevo |
| - | Remover | El bibliotecario remueve de la biblioteca el módulo nombrado |
| * | Extraer | El bibliotecario crea el archivo nombrado copiando el módulo correspondiente de la biblioteca al archivo |
| -* *- |
Extraer y Remover |
El bibliotecario copia el módulo designado al nombre de archivo correspondiente removiéndolo de la biblioteca |
| -+ +- |
Reemplazar | El bibliotecario reemplaza al módulo designado con el archivo correspondiente |
Con lo anterior, para crear una biblioteca nueva basta con agregar un módulo o varios módulos a la biblioteca que aún no existe, y el bibliotecario creará la biblioteca tras lo cual agregará los módulos. A modo de ejemplo, para crear una biblioteca llamada FUNCSQ.LIB desde la línea de comandos con los módulos F1.OBJ, F2.OBJ y F3.OBJ, escribimos lo siguiente4 en la línea de comandos (obsérvese que no es necesario ponerle la extensión .LIB al nombre del archivo FUNCS ya que será agregada automáticamente por el bibliotecario):
TLIB FUNCSQ +F1.OBJ +F2.OBJ +F3.OBJ
Si queremos crear la biblioteca FUNCSQ.LIB obteniendo al mismo tiempo un Listado de los contenidos de la misma en un archivo de texto con un mombre como FUNCS.LST, escribimos lo siguiente en la línea de comandos (obsérvese la coma que precede al archivo ):
TLIB FUNCSQ +F1.OBJ +F2.OBJ +F3.OBJ, FUNCS.LST
Para reemplazar el módulo F1.OBJ con una copia nueva (esto puede ocurrir en una operación de actualización de un módulo objeto), agregar el módulo F4.OBJ a la biblioteca FUNCSQ.LIB y eliminar el módulo F2.OBJ de la biblioteca, todo al mismo tiempo, escribimos:
TLIB FUNCSQ -+F1.OBJ +F4.OBJ -F2.OBJ
Para extraer el módulo F3.OBJ de la biblioteca (sin borrarlo) y obtener un listado actualizado, escribimos (obsérvese que las extensiones .OBJ son optativas) se escribe:
TLIB FUNCSQ *F3, FUNCS.LST
Suponiendo que los archivos fuente F1.C, F2.C, F3.C, etcétera ya han sido compilados individualmente a archivos objeto F1.OBJ, F2.OBJ, F3.OBJ, etcétera, podemos elaborar lo que se conoce como un archivo de responsiva que nos ayude en la creación de una biblioteca nueva que contenga los módulos objeto (y el cual tendrá un nombre como FUNCS.RSP en donde la extensión indica que se trata de un archivo de responsiva). El archivo de responsiva es un archivo de texto que contendrá algo como lo siguiente (obsérvense los símbolos ampersand “&” que hay que poner al final de cada línea de texto en el archivo de responsiva con la excepción de la última línea de texto, los símbolos + son requeridos por la sintaxis del bibliotecario para poder agregar módulos objeto a una biblioteca):
+C:\PROJECTS\FUNCS\F1.OBJ +C:\PROJECTS\FUNCS\F2.OBJ +C:\PROJECTS\FUNCS\F3.OBJ & +C:\PROJECTS\FUNCS\F4.OBJ +C:\PROJECTS\FUNCS\F5.OBJ +C:\PROJECTS\FUNCS\F6.OBJ & +C:\PROJECTS\FUNCS\F7.OBJ +C:\PROJECTS\FUNCS\F8.OBJ +C:\PROJECTS\FUNCS\F9.OBJ & +C:\PROJECTS\FUNCS\F10.OBJ
Podemos apreciar que para cada módulo objeto se proporciona la ruta completa (path) del sitio preciso en el disco duro (o en la memoria permanente que se esté usando, por ejemplo un dispositivo flash USB) en donde se puede encontrar archivado el módulo objeto. La observación más importante que se puede hacer es que el archivo de responsiva contiene 269 caracteres (el texto incluyendo los espacios en blanco). Resulta que en muchos sistemas operativos UNIX así como en las primeras computadoras caseras IBM PC XT e IBM PC AT que sentaron la pauta a seguir con el sistema operativo PC-DOS, la línea de comandos estaba limitada por el sistema operativo a un máximo de 128 caracteres. Si al usar el compilador C, el bibliotecario C o cualquier otra utilería C se encuentra que la lista de opciones y los nombres de archivos especificados con sus rutas completas exceden el límite máximo de 128 caracteres, entonces es necesario poner los nombres de los archivos en un archivo de responsiva que permite exceder el límite máximo de caracteres impuesto por la línea de comandos del sistema operativo. Esto fue lo que dió origen a los archivos de responsiva. Suponiendo que la especificación completa de los módulos objeto dados arriba con sus rutas completas está puesta el archivo de responsiva FUNCS.RSP, entonces sin necesidad de tener que recurrir a un entorno IDE se puede crear la biblioteca FUNCS.LIB que contendrá en una misma biblioteca los módulos objeto de las diez funciones, mediante la siguiente instrucción:
TLIB C:\LIBS\FUNCS.LIB @C:\RSP\FUNCS.RSP, C:\LIST\FUNCSL.LST
En la línea de comandos mostrada, se toma el archivo de responsiva FUNCS.RSP que está puesto en el disco duro C: dentro de la carpeta RSP, (el símbolo de la arroba “@” le indica al programa bibliotecario TLIB que se trata de un archivo de responsiva), el bibliotecario creará la biblioteca FUNCS.LIB y la pondrá en el disco duro C: dentro de la carpeta LIBS, y creará además un listado de los módulos objeto que fueron puestos en la biblioteca FUNCS.LIB, poniéndose el listado en el archivo de texto FUNCSL.LST que se encontrará en la carpeta LIST del disco duro C:. Si se abre con cualquier editor de texto (o procesador de palabras) el listado FUNCSL.LST, se encontrará algo como lo siguiente:
F1 size = 16
_F1
F10 size = 16
_f10
F2 size = 53
_f2
F3 size = 58
_f3
F4 size = 45
-f4
F5 size = 27
-f5
F6 size = 27
_f6
F7 size = 27
_f7
F8 size = 234
_f8
F9 size = 36
_f9
El listado le dice al programador que la biblioteca FUNCS.LIB contiene, por ejemplo, un módulo titulado F3.OBJ, el cual contiene una función C titulada f3().
Como alternativa de diseño para proyectos verdaderamente grandes en los cuales se producen módulos objeto que pueden ser reciclados con otros propósitos hacia otros proyectos, en lugar de una sola biblioteca en donde se pongan juntos todos los módulos objeto se pueden crear varias bibliotecas en las que se reúnan módulos objeto que puedan ser clasificados en forma distintiva. Inspirados en el ejemplo dado arriba al principio, podemos crear de la siguiente manera cuatro bibliotecas “hechas en casa” con el bibliotecario TLIB de Turbo C (supondremos que en el disco duro C: hemos creado una carpeta titulada OBJS en donde serán puestos los módulos objeto con los cuales se crearán las bibliotecas, y otra carpeta titulada LIBS en donde se irán poniendo las bibliotecas que vayan siendo creadas):
Biblioteca para conversión a caracteres ASII:
TLIB C:\LIBS\CHAR.LIB C:\OBJS\F1.OBJ
Biblioteca de funciones matemáticas:
TLIB C:\LIBS\MAT.LIB +C:\OBJS\F1.OBJ +C:\OBJS\F3.OBJ +C\OBJS\F4.OBJ
Biblioteca de funciones para manejo de hileras:
TLIB C:\LIBS\HIL.LIB +C:\OBJS\F5.OBJ +C:\OBJS\F6.OBJ +C\OBJS\F7.OBJ
Biblioteca de funciones de punteros:
TLIB C:\LIBS\PNT.LIB +C:\OBJS\F8.OBJ +C:\OBJS\F9.OBJ +C:\OBJS\F10.OBJ
El bibliotecario no es la única utilería que por su enorme utilidad incluyen muchos paquetes de compilación C. Existe otra utilería que puede examinar cualquier biblioteca para determinar cuáles son los módulos objeto que contiene una biblioteca. También puede examinar un archivo objeto para determinar los nombres públicos (variables y funciones globales) que contiene el archivo objeto. También puede examinar una lista de módulos objeto enlazándolos primero y determinando los contenidos públicos que corresponden a cada archivo objeto tras la resolución proporcionada por el enlazador (linker). El nombre dado a esta utilería varía de sistema a sistema, y uno de sus nombres es OBJXREF (OBJect module CROSS Reference), con la sintaxis:
OBJXREF [Opciones] Archivo Archivo...
La utilería genera un reporte que puede variar de acuerdo a opciones como las siguientes:
| Opción | Significado |
| /RC | Reporte según el tipo de la Clase |
| /RM | Reporte por Módulo: Los nombres públicos son agrupados y ordenados por módulo |
| /RP | Reporte por nombres Públicos: Los nombres públicos son puestos en orden junto con el nombre del módulo al que pertenecen |
| /RR | Reporte por Referencias: Las definiciones de nombres públicos y las referencias son puestos en orden de acuerdo con el nombre |
| /RS | Reporte de tamaños de módulos (Report of module Sizes): Los tamaños de los módulos son ordenados de acuerdo con el nombre del segmento |
| /RU | Report of Unreferenced symbol names (para símbolos no-referenciados) |
| /RX | Reporte por referencia externa |
A modo de ejemplo, si desde una ventana de líneas de comandos recurrimos a la utilería OBJXREF para examinar con la siguiente línea los contenidos de la biblioteca FUNCSQ.LIB creada arriba (la opción “/F” que representa “Full” es usada para generar un reporte completo):
OBJXREF /F /RP C:\LIBS\FUNCSQ.LIB
se genera un reporte como el siguiente:
PUBLIC SYMBOL DEFINITIONS BY SYMBOL NAME SYMBOL DEFINED IN FIDRQQQ -undefined- FIWRQQ -undefined- _f1 F1 (FUNCSQ) -f10 F10 (FUNCSQ) _f2 F2 (FUNCSQ) _f3 F3 (FUNCSQ) -f4 F4 (FUNCSQ) _f5 F5 (FUNCSQ) _f6 F6 (FUNCSQ) _f7 F7 (FUNCSQ) -f8 F8 (FUNCSQ) _f9 F9 (FUNCSQ) _log10 -undefined- _printf -undefined- -sqrt -undefined- --turboFloat -undefined- Symbols = 16 Modules = 11
En el ejemplo que se ha dado arriba, hemos visto cómo la utilería OBJXREF es usada para inspeccionar los contenidos de una biblioteca. Pero se había afirmado también que la misma utilería puede ser utilizada para inspeccionar los contenidos de archivos objeto (archivos con la extensión .OBJ). Si aplicamos la utilería OBXREF al programa que vimos al principio que consta de dos módulos, ya compilados por separado y con los nombres MODULO1.OBJ y MODULO2.OBJ, usando el comando (supondremos que los archivos objeto han sido guardados en el disco duro en una carpeta titulada OBJS):
OBJXREF /RP C:\OBJS\MODULO1.OBJ C:\OBJS\MODULO2.OBJ
entonces la utilería produce el siguiente listado:
PUBLIC SYMBOL DEFINITIONS BY SYMBOL NAME SYMBOL DEFINED IN peso(float) MODULO1 salida() MODULO2 FIDRQQ -undefined- FIWRQQ -undefined- _a MODULO1 -b MODULO2 _exit -undefined- _Factor MODULO1 -main MODULO1 _x1 MODULO1 _x2 MODULO1 _x3 MODULO2 Symbols = 12 Modules = 3
Apenas hemos tocado la superficie de la rica variedad de utilerías originalmente disponibles en UNIX y las cuales a través de la popularidad del lenguaje C continúan siendo usadas con algún cambio ligero de nombre para facilitar la labor de los programadores profesionales. Una de tales utilerías es la utilería de retoque de fecha y tiempo con un nombre como TOUCH, la cual se requiere en algunos proyectos en los cuales el entorno IDE se rehúsa a compilar un proyecto porque uno de los archivos no ha sido actualizado con respecto a los demás (cuando se compila un proyecto con varios archivos separados, el compilador le anexa a cada archivo objeto la hora y fecha de creación de acuerdo al reloj del sistema). En los sistemas operativos DOS (así como en las emulaciones de los mismos), la información de la hora y fecha de cualquiera de los archivos guardados en el sistema es obtenida del simple listado de la carpeta en donde se encuentra el archivo que nos interesa. Por otro lado, podemos obtener del sistema la fecha actual con el comando DOS date y la hora actual con el comando DOS time. Invocando la utilería TOUCH, podemos estamparle al archivo que queramos la hora y fecha actualizada, sin necesidad de tener que volver a compilar el archivo fuente a un archivo objeto (y he aquí en donde se logra el ahorro de tiempo) en cada ocasión que se requiera producir el programa ejecutable final.
Existe una variedad de utilerías importantes derivadas del sistema operativo UNIX que han sido incorporadas dentro de muchos sistemas operativos y entornos de programación, implementadas frecuentemente con nombres parecidos o con los mismos nombres, disponibles a todo programador cuya experiencia le permite prescindir de entornos integrados de desarrollo IDE, cuya existencia puede serle de gran utilidad a los programadores profesionales. Estas utilerías a veces son agregadas como accesorios cuya existencia es mencionada brevemente en los manuales de programación que acompañan cada producto de software de compilación.
¿Y por qué razón, habiendo disponibles entornos integrados de desarrollo IDE que dan mayor comodidad a la frecuentemente ardua tarea de programación de computadoras, estaría en disposición un programador a recurrir a estas utilerías que solo funcionan a través de una ventana de líneas de comandos? Quizá la razón más importante es que, en caso de problemas serios, la interfaz visual de sistemas operativos como Windows en vez de ser una ayuda puede ser un estorbo, porque el programador no está seguro si un problema grave se pueda deber a un fallo suyo o a una incompatibilidad con el sistema operativo de la máquina que no depende de lo correcto que haya sido elaborado el código. Y es en situaciones como ésta que reduciendo todo al mínimo absoluto, quitándole la farfalá y los adornos visuales a lo que esperamos de un programa, podemos localizar algo que se puede deber a un algoritmo mal diseñado o a una porción de código que genera un ejecutable incompatible con el modelo de memoria que se está usando.
Con el lenguaje C podemos escribir el código fuente para construír cualquier cosa, lo cual incluye un programa ejecutable que pueda convertir código fuente escrito en un lenguaje como FORTRAN a su equivalente en lenguaje de máquina con cierto procesador CPU específico como destinatario para la ejecución de programas escritos en FORTRAN. En pocas palabras, podemos construír un compilador FORTRAN. Y también podemos construír un compilador BASIC. ¡Y también podemos construír hasta un compilador C (recuérdese que un compilador es un programa ejecutable) capaz de tomar código fuente en C convirtiéndolo a código ejecutable en lenguaje de máquina!
No reproduciremos aquí el código fuente escrito en C de un compilador FORTRAN o de un compilador BASIC porque algo así tiende a consumir decenas de miles de líneas de código fuente y ayuda muy poco en la comprensión didáctica de las tareas que se llevan a cabo en un compilador. Pero sí podemos asentar un compilador elemental menos ambicioso que ilustre los principios genéricos de lo que entendemos por compilación, la conversión automatizada de algo escrito en código fuente en algún lenguaje como FORTRAN a su equivalente capaz de ser ejecutado en lenguaje de máquina por alguna computadora. Para ello, tomaremos un ejemplo introductorio que abre el libro Compilers: Principles, techniques and tools de Alfred Aho, Ravi Sethi y Jeffrey D. Ullman, que puede tomar expresiones matemáticas introducidas desde una ventana de líneas de comandos y que puede “descomponer” una “oración” matemática convirtiéndola a algo que puede ser procesado por una computadora. Pero antes de presentar dicho ejemplo, haremos un repaso rápido de lo que se lleva a cabo en el programa.
El primer paso de cualquier compilador consiste, desde luego, en llevar a cabo el “análisis gramatical” de cada instrucción de un programa a ser compilado, como si fuese una oración (obviamente, un programa extenso contendrá muchas “oraciones”), verificando que cada oración esté construída correctamente de acuerdo a las reglas de la gramática del lenguaje, ya que de lo contrario en caso de haber una “oración” mal formada el programa no podrá ser convertido a su equivalente en lenguaje de máquina y se tendrá que generar un mensaje de error. Al llevarse a cabo el análisis gramatical, se lleva a cabo el proceso de parsificación del programa fuente, un proceso que consiste esencialmente en tomar un archivo de texto legible que es legible para cualquier humano, identificando todos los tokens que hay en el archivo de texto (las etiquetas simbólicas que hay en el texto así como las palabras reservadas usadas por el lenguaje tales como for y while), y una vez hecho esto se puede efectuar una conversión de una expresión matemática de su forma infija (la forma en la cual está originalmente escrita la expresión a lo largo de una línea horizontal) a su forma postfija (removiendo los paréntesis y acomodando los datos en forma procesable por la computadora), hacia lo que se conoce como la notación polaca inversa (RPN, Reverse Polish Notation). Eventualmente se construye con ésto un árbol para cada expresión a ser evaluada, llegando finalmente a algo que se asemeja mucho a un programa escrito en lenguaje ensamblador, el cual a su vez es pasado directamente por el compilador a un programa ensamblador que llevará a cabo el proceso de ensamble convirtiendo el código intermedio en código ejecutable en lenguaje de máquina. Y a diferencia del programa original escrito en texto en lenguaje de alto nivel que se puede transportar de una computadora a otra distinta con cambios mínimos en el código fuente, el programa en lenguaje de máquina sólo puede ejecutarse en computadoras que tengan arquitecturas compatibles y que tengan el mismo conjunto de instrucciones disponibles en lenguaje de máquina. Esto último es dependiente de cada máquina y se vuelve imposible hacer una generalización. Sin embargo, el primer paso, el paso de parsificación, es razonablemente “universal”, y se puede escribir un parsificador en lenguaje C que puede servir como el preliminar de un compilador completo. Y es una de las cosas que hace el compilador cuyo código fuente será reproducido abajo.
A continuación se presenta el código fuente de un compilador elemental, tomado del libro Compilers: Principles, techniques and tools escrito por Alfred Aho, Ravi Sethi y Jeffrey D. Ullman:
Archivo de cabecera GLOBAL.H:
#include "stdio.h" /* load i/o routines */
#include "ctype.h" /* load character test routines */
#include "string.h" /* load string handling routines */
#define BSIZE 128
#define NONE -1
#define EOS '\0'
#define NUM 256
#define DIV 257
#define MOD 258
#define ID 259
#define DONE 260
struct entry { /* form of symbol table
entry */
char *lexptr;
int token;
};
Archivo LEXER.C:
#include "global.h"
extern struct entry symtable[];
extern error();
char lexbuf[BSIZE];
int lineno = 1;
int tokenval = NONE;
int lexan() /* lexical analyzer */
{
int t;
while(1) {
t = getchar();
if (t == ' ' || t == '\t')
; /* strip out white space */
else if (t == '\n')
lineno = lineno + 1;
else if (isdigit(t)) { /* t is a digit */
ungetc(t, stdin);
scanf("%d", &tokenval);
return NUM;
}
else if (isalpha(t)) { /* t is a letter */
int p, b =0;
while (isalnum(t)) { /* t is alphanumeric */
lexbuf[b] = t;
t = getchar();
b = b + 1;
if (b >= BSIZE)
error("compiler error");
}
lexbuf[b] = EOS;
if (t != EOF)
ungetc(t, stdin);
p = lookup(lexbuf);
if (p == 0)
p = insert(lexbuf, ID);
tokenval = p;
return symtable[p].token;
}
else if (t == EOF)
return DONE;
else {
tokenval = NONE;
return t;
}
}
}
Archivo PARSER.C:
#include "global.h"
extern int tokenval;
extern int lexan();
extern char emit();
extern char error();
extern struct entry symtable[];
int lookahead;
void parse() /* parses and translates
expression list */
{
lookahead = lexan();
while ( lookahead != DONE ) {
expr(); match(';');
}
}
expr()
{
int t;
term();
while(1)
switch (lookahead) {
case '+' : case '-':
t = lookahead;
match(lookahead); term(); emit(t, NONE);
continue;
default:
return;
}
}
term()
{
int t;
factor();
while(1)
switch (lookahead) {
case '*': case '/': case DIV: case MOD:
t = lookahead;
match(lookahead); factor(); emit(t, NONE);
continue;
default:
return;
}
}
factor()
{
switch (lookahead) {
case '(':
match('('); expr(); match(')'); break;
case NUM:
emit(NUM, tokenval); match(NUM); break;
case ID:
emit(ID, tokenval); match(ID); break;
default:
error("Syntax error");
}
return 0;
}
match(int t)
{
if (lookahead == t)
lookahead = lexan();
else error("Syntax error");
return 0;
}
Archivo EMITTER.C:
#include "global.h"
extern struct entry symtable[];
void emit(int t, int tval) /* generates output */
{
switch(t) {
case '+': case '-': case '*': case '/':
printf("%c\n", t); break;
case DIV:
printf("DIV\n"); break;
case MOD:
printf("MOD\n"); break;
case NUM:
printf("%d\n", tval); break;
case ID:
printf("%s\n", symtable[tval].lexptr); break;
default:
printf("token %d, tokenval %d\n", t, tval);
}
}
Archivo SYMBOL.C:
#include "global.h"
#define STRMAX 999 /* size of lexemes array */
#define SYMMAX 100 /* size of symtable */
char lexemes[STRMAX];
int lastchar = -1; /* last used position in lexemes */
struct entry symtable[SYMMAX];
int lastentry = 0; /* last used position in symtable */
int lookup(s) /* returns position of entry for s */
char s[];
{
int p;
for (p = lastentry; p > 0; p = p - 1)
if (strcmp(symtable[p].lexptr, s) == 0)
return p;
return 0;
}
int insert(s, tok) /* returns position of entry for s */
char s[];
int tok;
{
int len;
len = strlen(s); /* strlen computes length of s */
if (lastentry + 1 >= SYMMAX)
error("symbol table full");
if (lastchar + len + 1 >= STRMAX)
error("lexemes array full");
lastentry = lastentry + 1;
symtable[lastentry].token = tok;
symtable[lastentry].lexptr = &lexemes[lastchar + 1];
lastchar = lastchar + len + 1;
strcpy(symtable[lastentry].lexptr, s);
return lastentry;
}
Archivo INIT.C:
#include "global.h"
extern struct entry symtable[];
extern int insert();
struct entry keywords[] = {
"div", DIV,
"mod", MOD,
0, 0
};
void init() /* loads keywords into symtable */
{
struct entry *p;
for (p = keywords; p->token; p++)
insert(p->lexptr, p->token);
}
Archivo ERROR.C:
#include "global.h"
extern int lineno;
void error(m) /* generates all error messages */
char *m;
{
fprintf(stderr, "line %d: %s\n", lineno, m);
exit(1); /* unsuccessful termination */
}
Archivo MAIN.C:
#include "global.h"
extern init();
extern parse();
int main()
{
init();
parse();
return(0); /* successful termination */
}
El programa, cuando se ejecuta, puede tomar una línea de texto (como lo hace un compilador) llevando a cabo una parsificación de una expresión sobre la que se efectúa un análisis léxico descomponiéndola en sus partes esenciales o tokens, construyéndose una tabla de símbolos tal y como se hace en muchos compiladodres, y produciendo una “pila” (stack) en donde son colocados los en notación postfix los símbolos de la expresión. En pocas palabras, se tienen todos los componentes esenciales que encontramos en prácticamente cualquier compilador. Y si podemos entender algo como ésto, podemos emprender cualquier proyecto de programación en el que pongamos nuestro empeño.
Lo que hemos visto en esta entrada nos permite poner manos a la obra para familiarizarnos con este programa.
PROYECTO: (1) Procurar un compilador o un entorno IDE C, y compilar el código C reproducido arriba que fue tomado del libro Compilers: Principles, techniques and tools de Aho, Sethi y Ullman, para obtener un archivo ejecutable al que se le llamará COMPILER.EXE (aunque todo el código repartido arriba en varios archivos se puede juntar y poner dentro de un mismo archivo, el objetivo es familiarizarse con proyectos en los que se mantienen varios archivos separados ). (2) ¿Cuál será el resultado obtenido cuando al programa COMPILER.EXE se le entreguen las siguientes expresiones matemáticas? (obtener las respuestas corriendo el programa ejecutable obtenido usando las expresiones proporcionadas):
(3+5+1)*10;
(500-a+b)/(x*y);
((base*altura)/2)*profundidad;
450 div 89 mod 4;
((a+b)*(c+d))/((x+y)*(w+z));
Si se compila el código a un archivo ejecutable llamado COMPILER.EXE, se abre la ejecución del archivo ejecutable desde una ventana de líneas de comandos y se le van entregando las expresiones proporcionadas (obsérvese que se requiere un semicolon al final de cada expresión), entonces se va obteniendo la conversión (compilación) de cada expresión matemática a su equivalente en forma de notación polaca con los identificadores acomodados verticalmente en una pila (stack), de la manera mostrada:
| Entrada | Salida |
| (3+5+1)*10; | 3 5 + 1 + 10 * |
| (500-a+b)/(x*y); | 500 a - b + x y * / |
| ((base*altura)/2)*profundidad; | base altura * 2 / profundidad * |
| 450 div 89 mod 4; (los identificadores div y mod tienen que estar en minusculas) |
450 89 DIV 4 MOD |
| ((a+b)*(c+d))/((x+y)*(w+z)); | a b + c d * x y + w z + * / |
Como puede verse, al compilador que hemos visto escrito en C le faltan algunos detalles que quedaron pendientes. Al darle a la computadora una expresión como:
(3+5+1)*10
para su evaluación, esperamos que la computadora nos dé una respuesta como 90. Sin embargo, inspeccionando la forma en la que están acomodados los identificadores en cada pila (simbólica), podemos ver que las expresiones en las que hay valores numéricos están listas para ser procesadas de inmediato por cualquier computadora por primitiva que sea, observándose que los paréntesis en todas las expresiones han sido removidos por el compilador y lo que hay en cada pila está listo para su evaluación por el CPU. Para el ejemplo mostrado, la evaluación procede del siguiente modo (la computadora busca en la pila yendo desde el tope hacia abajo tomando los primeros operandos que encuentra, y deteniéndose al encontrar el primer operador que encuentra, aplicando la operación matemática correspondiente y poniendo el resultado en el tope de la pila, para repetir nuevamente el procedimiento hasta que no haya más operadores):

Y en el caso en donde las expresiones han sido parsificadas por el programa no acomodando valores numéricos sino etiquetas simbólicas como “base”, “altura” y “profundidad”, se supone que previamente, en un compilador más completo elaborado a partir del código que se ha proporcionado arriba, se han suministrado previamente valores numéricos para cada una de las variables que pueden ser acomodados en una tabla, lo cual permite substituír todas las etiquetas simbólicas que haya en la pila por valores numéricos con lo cual se puede efectuar la evaluación matemática de la expresión para obtener un resultado numérico.
Un programa computacional de uso práctico permite la inclusión no de una sola instrucción que contenga una expresión matemática sino muchas, y para cada una de ellas se requerirá la construcción intermedia de su propia tabla, lo cual permite vislumbrar que el proceso de conversión de un programa escrito en código fuente en cualquier lenguaje computacional a su equivalente en lenguaje de máquina involucrará la construcción de muchas tablas intermedias.
Resultará de interés para muchos lectores el saber que, antes del advenimiento de las computadoras personales caseras, cuando la fabricación y venta de calculadoras científicas programables de bolsillo estaba en boga, había una empresa que fabricaba calculadoras de bolsillo en las cuales, a diferencia de las calculadoras científicas fabricadas por la empresa Texas Instruments (como la calculadora TI-58 y la calculadora TI-59) en donde la entrada de datos en una expresión matemática se efectuaba en modo semejante a como se acostumbra hacerlo con la notación algebraica ordinaria, la entrada de los datos se llevaba a cabo usando precisamente la notación polaca inversa. Era la empresa Hewlett-Packard, y la primera calculadora de este tipo fue la calculadora HP-35, la cual dicho sea de paso fue la primera calculadora científica de bolsillo del mundo, lo cual marcó un hito significativo en el desarrollo tecnológico del hombre en el área de la informática que comenzó con la máquina analítica concebida por Charles Babbage y la cual usaba como fuente de energía una máquina de vapor. La invención de lenguajes de computadora de alto nivel y entornos de programación IDE culminó con el ciclo que ha sido responsable de impulsar al hombre hacia el sitio privilegiado que hoy ocupa en el tercer milenio.
Hemos cubierto los rudimentos de lo que se requiere para emprender un proyecto de compilación serio y grande usando el lenguaje C como plataforma de desarrollo. De hecho, y hablando en términos generales, no se requiere de más herramientas para llevar a cabo cosas como las que están logrando empresas fuertes como Microsoft y Apple. Lo que se requiere es algo de ingenio. Pero esto último no es algo que se pueda enseñar, es algo que se tiene que ir desarrollando con la práctica y con mucha, mucha paciencia.