El concepto detrás de la arquitectura RISC se originó durante 1974 por John Cocke, investigador asociado al Centro de Investigación de IBM T. J. Watson, el cual descubrió tras un estudio exhaustivo del comportamiento y uso en el campo (comercios, escuelas, laboratorios, etc.) de muchos programas de aplicación que la computadora típica utiliza en promedio únicamente el 20% de su conjunto de instrucciones para llevar a cabo el 80%n de su trabajo. Las consecuencias de este descubrimiento son que los conjuntos complejos de instrucciones no eran una necesidad absoluta, y antes bien podían ser considerados como un avance superfluo. Obtenida esta conclusión, el siguiente paso fue convertirla en realidad y probarla. El primer sistema RISC se materializó en el diseño y construcción de la computadora IBM 801 iniciado en 1975 tomando como base las conclusiones de John Cocke. Y a partir de entonces se originó un debate entre quienes apoyan el uso de la filosofía RISC para el diseño y construcción de las computadoras que vengan en el futuro, y quienes opinan que por el contrario la filosofía adoptada principalmente por la empresa fabricante de microprocesadores Intel de que hay que hacer al procesador CPU cada vez más y más complejo metiéndole cantidades cada vez mayores de componentes lógicos según lo permita la tecnología. Este segundo grupo de expertos respalda lo que se conoce como la filosofía CISC (Complex Instruction Set Computer).
Antes de entrar en mayores detalles, es necesario aclarar lo que no puede ser tomado por sí solo como un incremento oneroso en la complejidad de las computadoras, y esto involucra el tamaño de la palabra binaria que puede ser manejada por una unidad de procesamiento central. En un principio, la palabra binaria básica era el byte, un dato binario representado por ocho bits, como 10011101. Aunque si bien es cierto que solo se requiere de una palabra formada por cuatro bits, referida en algunos textos como un nibble, para representar cualquier número del cero (0000) al nueve (1001), que dicho sea de paso es lo que utilizan muchas calculadoras de bolsillo para sus cálculos aritméticos, para poder asignarle a un código binario a todos los caracteres propios del alfabeto en base a alguna convención como el código ASCII se requiere forzosamente de una cantidad mayor de bits, lo cual permite usar una computadora no solo para tareas puramente numéricas sino para poder llevar a cabo la ejecución de programas elaborados en lenguajes de alto nivel comprensibles a los humanos. Y en el mundo de la aritmética binaria, lo usual es aumentar la capacidad de una palabra binaria especificándola como un múltiplo de 2. Por lo tanto, un byte es lo mínimo que se requiere que pueda manejar cualquier computadora, inclusive una primitiva para nuestros días.
Si por avances en la tecnología y la consecuente reducción de costos se puede aumentar la capacidad de la unidad de lógica y aritmética ALU del procesador central para que pueda sumar números de 16 bits en lugar de números de 8 bits, ello se puede llevar a cabo sin mucha pena ya que solo se requiere aumentar la capacidad de algunos registros internos del CPU (como el acumulador) de 8 bits a 16 bits, y aumentar la capacidad de unidades como el bloque de sumación conectando en cascada 16 medios-sumadores en lugar de 8 medios-sumadores. Lo importante es que estos incrementos no inciden mucho en el diseño de la unidad de control del CPU. El siguiente paso de refinamiento consiste en aumentar la capacidad del acumulador y otros bloques del CPU para poder manejar palabras binarias de 32 bits en lugar de 16 bits, lo cual se puede llevar a cabo sin muchos problemas y sin tener que aumentar en forma desmesurada la complejidad del CPU. Sin embargo, si se quiere mantener compatibilidad “hacia abajo” para que una computadora que ahora puede manejar instrucciones de 16 bits pueda seguir ejecutando los programas elaborados para instrucciones de 8 bits que podía efectuar antes, será necesario agregar instrucciones adicionales al conjunto de instrucciones previo. En pocas palabras, se espera que el número de instrucciones crezca, lo cual en un principio puede ser ventajoso cuando se trata de mantener compatibilidad.
El problema sobreviene cuando, además de la capacidad en el número de bits que defina la palabra binaria que sea capaz de manejar un procesador, queremos aumentar el conjunto de instrucciones que pueden ser interpretadas por el CPU incluyendo instrucciones que puedan llevar a cabo tareas cada vez más sofisticadas. Esto sí es algo que puede incidir y de manera dramática en el diseño y complejidad del CPU, porque cada instrucción adicional que por su sofisticación requiera de la ejecución de una cantidad múltiple de varios “ciclos de reloj” involucra la necesidad de “grabar” en la memoria permanente de la unidad de control tales microinstrucciones, incrementando la complejidad del mismo.
Veamos ahora cómo puede irse dando un aumento en la complejidad de la arquitectura de una computadora a grado tal que dicho aumento en complejidad termine siendo una carga onerosa y que irónicamente pueda resultar superflua.
La manera más sencilla de examinar las ventajas y desventajas de la arquitectura RISC es contrastándola con la arquitectura de su competidora la arquitectura CISC. Veamos el caso de la multiplicación de dos números que están guardados en la memoria. A continuación se muestra un diagrama que representa el esquema general de almacenamiento de una computadora genérica:

La memoria principal está dividida en localidades numeradas desde (renglón) 1: (columna) 1 hasta (renglón) 6: (columna) 4, lo cual podemos especificar con un poco más de detalle:
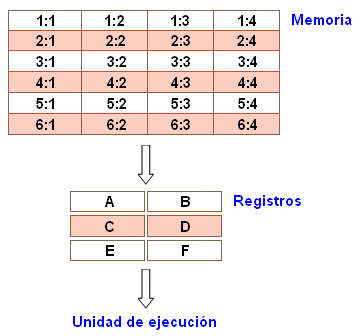
La unidad de ejecución es la encargada de llevar a cabo todos los cómputos. Sin embargo, la unidad de ejecución solo es capaz de operar sobre datos que han sido cargados previamente en alguno de los seis registros (A, B, C, D, E o F). Supóngase que queremos encontrar el producto de dos números, uno de ellos almacenado en la localidad 2:3 y el otro almacenado en la localidad 5:2, almacenando el producto obtenido en la localidad 2:3.
En el procedimiento CISC, el objetivo fundamental de la arquitectura es llevar a cabo la tarea usando la menor cantidad de líneas de código de ensamble que sea posible. Esto se logra construyendo un procesador cuyo hardware sea capaz de entender y ejecutar una serie de operaciones. Para esta labor específica, un procesador CISC estaría equipado con una instrucción específica que llamaremos MULT. Al ser ejecutada, esta instrucción carga los dos valores a ser multiplicados en dos registros separados, multiplica los operandos en la unidad de ejecución, y almacena el producto en el registro apropiado. De este modo, la tarea completa de llevar a cabo la multiplicación de los dos números puede ser llevada a cabo con una sola instrucción:
MULT 2:3 5:2
La instrucción MULT es lo que se conoce como una “instrucción compleja”. Opera directamente sobre los bancos de memoria de la computadora y no requiere que el programador invoque explícitamente ninguna función para llevar a cabo el almacenamiento o cargado de datos. Se asemeja a un instrucción típica de un lenguaje de alto nivel. Por ejemplo, si dejamos que “a” represente el valor de 2:3 y que “b” represente el valor de 5:2, entonces este comando es idéntico al enunciado en lenguaje C expresado como “a = a*b”.
Una de las principales ventajas de este sistema es que el programa compilador tiene que hacer muy poco trabajo para convertir este enunciado en lenguaje de alto nivel a un código en lenguaje ensamblador. Puesto que la longitud del código es relativamente breve, se requiere muy poca memoria RAM para almacenar las instrucciones. El énfasis está en construír instrucciones complejas directamente en el hardware.
Ahora veamos cómo se lleva a cabo lo anterior usando la metodología RISC.
Los procesadores RISC utilizan únicamente instrucciones sencillas que pueden ser ejecutadas en un ciclo de reloj. En un procesador RISC no existe una instrucción como MULT, y la forma de implementarla en una computadora RISC es dividiéndola en tres comandos separados: “LOAD”, que mueve un dato de un banco de la memoria a un registro, “PROD”, que encuentra el producto de dos operandos localizados en los registros, y “STORE” que mueve un dato de un registro a los bancos de memoria.
Para poder llevar a cabo la misma secuencia de cómputo que la que se lleva a cabo bajo la metodología CISC, un programador necesitaría de cuatro líneas de código en lenguaje ensamblador como las siguientes:
LOAD A, 2:3
LOAD B, 5:2
PROD A, B
STORE 2:3, A
A primera vista, esto parece ser una manera mucho menos eficiente de completar la operación. Puesto que hay más líneas de código, se requiere de una cantidad mayor de memoria RAM para almacenar las instrucciones en lenguaje ensamblador. El programa compilador también tiene que hacer más trabajo para convertir un enunciado en lenguaje de alto nivel a código de esta forma. Sin embargo, y esto es importante, al recurrir directamente a las instrucciones primitivas sin tratar compactarlas en una “instrucción compleja” estamos evitando el tener que rediseñar la unidad de control del procesador central CPU para poder manejar la instrucción compleja.
Podemos establecer las siguientes comparaciones:
CISC
|
RISC
|
| Énfasis en el hardware | Énfasis el el software |
| Incluye instrucciones complejas que ocupan varios ciclos de reloj |
Usa solo instrucciones reducidas que ocupan un ciclo de reloj |
| Operación memoria a memoria: LOAD y STORE están incorporadas en las instrucciones complejas |
Operación registro a registro: LOAD y STORE son instrucciones independientes |
| Tamaños pequeños de código en la memoria RAM |
Tamaños grandes de código en la memoria RAM |
| Más hardware requerido para la ejecución de instrucciones complejas |
Más recursos requeridos en los bancos de memoria RAM |
Como ya se dijo, la estrategia RISC trae consigo algunas ventajas importantes. Puesto que cada instrucción requiere un solo ciclo de reloj para ejecutarse, el código completo se ejecutará en aproximadamente la misma cantidad de tiempo que el comando CISC de multiplicación “MULT”, cuyo procesamiento requiere de varios ciclos de reloj. Las “instrucciones reducidas” RISC requieren menos componentes en el espacio de hardware que las instrucciones complejas, dejando más campo para registros de propósito general. Puesto que todas las instrucciones se ejecutan en un monto uniforme de tiempo (un ciclo de reloj), esto permite implementar la técnica conocida como pipelining (se pronuncia “paiplaining”):
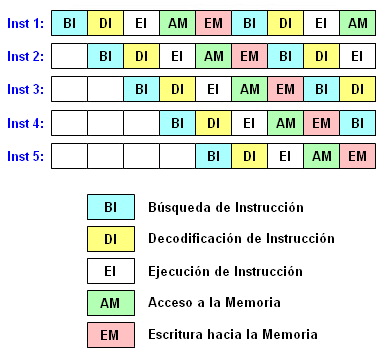
Típicamente, después de que ha concluído la ejecución de una instrucción, comienza la ejecución de la siguiente instrucción. Pero en los procesadores que dan soporte a la técnica de pipelining, el tiempo de ejecución de una instrucción es subdividido en varias etapas (ciclos de máquina). Tan pronto como una etapa ha terminado, la máquina continúa ejecutando la segunda etapa. Sin embargo, cuando el escenario se encuentra libre, puede ser utilizado para ejecutar la misma operación que pertenece a la siguiente instrucción. La operación sucesiva de instrucciones es llevada a cabo de una manera parecida a una línea de ensamble de un proceso de manufactura que va siendo alimentada por líneas de entrada diferentes conforme avanza la banda transportadora. La figura anterior muestra un escenario de cinco traslapes. Al traslaparse la ejecución de varias instrucciones, RISC logra un paralelismo inherente de ejecución que es responsable por la ventaja que toma sobre las computadoras que utilizan la metodología CISC y en las cuales no es posible lograr tal traslape porque las instrucciones de una computadora CISC requieren más de un ciclo de reloj para poder ejecutarse.
Separando las instrucciones de carga “LOAD” y de almacenamiento “STORE” de hecho disminuye la carga de trabajo que la computadora debe llevar a cabo. Después de que una instrucción de tipo-CISC “MULT” es ejecutada, el procesador borra automáticamente los registros. Si uno de los operandos tiene que ser usado para otro cálculo, el procesador tiene que volver a cargar el dato del banco de la memoria hacia un registro. En RISC, el operando permanecerá en el registro hasta que otro valor sea cargado en su lugar.
Antes de que la filosofía RISC hiciera su aparición, en los inicios de las primeras computadoras electrónicas, la programación se llevaba a cabo primordialmente usando un lenguaje ensamblador (en código de máquina), y esto promovía la implementación de instrucciones que fueran potentes y fáciles de utilizar. Por lo tanto, los diseñadores de las unidades de procesamiento central CPU trataron de hacer que las instrucciones hicieran tanto trabajo como fuese posible. Con el advenimiento de los lenguajes de alto nivel, los arquitectos de las computadoras empezaron también a crear instrucciones dedicadas a implementar en forma directa diversos mecanismos para apoyar al nivel de hardware tales lenguajes. Otro objetivo era proporcionar cualquier modo de domiciliamiento posible para cada instrucción. Puesto que el diseño del hardware estaba mucho más fundamentado y comprendido que el diseño de compiladores, los diseñistas trataron de implementar partes de funcionalidad en hardware en lugar de implementarlas en un compilador trabajando con recursos de memoria RAM sumamente limitados en aquellos tiempos. Puesto que las primeras máquinas eran programadas en lenguaje ensamblador y la memoria era lenta y cara, el énfasis sobre la filosofía CISC tenía su razón de ser, y tal filosofía era implementada en computadoras grandes (para los estándares de aquél entonces) tales como la PDP-11 y las máquinas DECSystem 10 y DECSystem 20. La lentitud en los accesos a la memoria fue un acicate para que los diseñistas crearan máquinas con conjuntos de instrucciones que redujeran la frecuencia de accesos a la memoria. Por otro lado, los tamaños limitados de la memoria (una memoria de 1 Gigabyte hubiera sido impensable en aquellos tiempos) solo admitían programas relativamente pequeños (para nuestros estándares actuales), lo cual alentaba conjuntos de instrucciones densos y complicados.
Después de que la filosofía RISC obtuvo su nombre, la filosofía pre-RISC de estarle agregando al conjunto de instrucciones de los procesadores tantas instrucciones como fuese posible llevando a cabo no una sino muchas operaciones con la invocación de una sola “megainstrucción” encargada de implementar en hardware las muchas operaciones recibió retroactivamente el nombre CISC casi como una burla. La intención original detrás de CISC era simplificar la construcción de los compiladores enviando al hardware tanto como fuese posible de lo que se llevaba a cabo mediante software, mejorando el desempeño bajo limitaciones tales como memorias RAM pequeñas y lentas. CISC desplaza la carga de generar muchas instrucciones en lenguaje de máquina hacia el procesador simplificando con ello la elaboración de los programas compiladores. Un ejemplo que ilustra esto es la extracción de la raíz cuadrada de un número, por ejemplo:
√58937 = 242.7694
La extracción de la raíz cuadrada de un número (y supondremos que se trata de un número que no tiene raíz cuadrada exacta, esto es, un entero cuyo cuadrado sea igual al número al que se le extrae raíz cuadrada) se puede llevar a cabo mediante un procedimiento o algoritmo que haya sido estipulado previamente. Un algoritmo frecuentemente enseñado en las escuelas primarias y secundarias y que ya había sido introducido en una entrada previa titulada “Algoritmos computacionales” es el conocido en México como el “método del Profesor Chema”, y el cual será reproducido aquí nuevamente:
1. Se divide el número (de derecha a izquierda) en períodos de dos cifras; el último período de la izquierda puede constar de una cifra:
58937 = 5,89,37
2. Se le saca la raíz cuadrada al primer período (ignorando fracciones decimales en caso de que las haya):
√5 = 2....
3. Se saca el primer residuo, restando del primer período el cuadrado de la raíz encontrada:
5 - 22 = 1
4. Se baja el siguiente período a continuación del primer residuo y se duplica la raíz.
5. Separando una cifra del número formado por el primer residuo y el segundo período (189), se divide entre el duplo de la raíz. El cociente se escribe en tres lugares, que son: (a) a continuación de la primera cifra de la raíz, (b) junto al duplo de la raíz, (c) para multiplicar el número formado con el duplo de la raíz.
6. El producto se resta para encontrar el segundo residuo.
7. Se baja el siguiente período, se duplica la raíz y se repiten los pasos 5 y 6 hasta terminar.
A continuación se presenta un gráfico animado que ilustra la secuencia de pasos en la implementación del algoritmo:

Esta es una manera en la que las calculadoras y las computadoras pueden obtener la raíz cuadrada de un número. El algoritmo anterior puede ser codificado en una serie de pasos para dárselos a la máquina para que ésta lleve a cabo las operaciones haciendo todo el trabajo por nosotros, usando operaciones como LOAD (carga de un dígito o grupo de dígitos numéricos que se encuentren en la memoria), STORE (almacenamiento de un resultado parcial en la memoria), PROD (operación para multiplicar dos números en la unidad de aritmética y lógica del procesador) y DIV (operación para dividir dos números). En términos de las cuatro operaciones aritméticas elementales de suma, resta, multiplicación y división, podemos ver que la extracción de la raíz cuadrada de un número como 5761897 para obtener una respuesta con una precisión de diez cifras significativas (2400.395176) se llevará un buen número de instrucciones aritméticas en lenguaje de máquina, posiblemente más de cien instrucciones, esto además de las operaciones intermedias de almacenamiento de resultados temporales en la memoria. El almacenamiento de cien instrucciones necesariamente consume cien localidades en la memoria RAM, y diseñar un programa compilador para que tome una instrucción de alto nivel como RAIZ convirtiéndola en cien instrucciones en lenguaje de máquina necesariamente impondrá una carga adicional de complejidad a la construcción del compilador. Pero si hacemos al procesador más complejo en forma tal que en su conjunto de instrucciones haya una instrucción como SQRT que simplemente vaya tomando cada uno de los seis u ocho dígitos del número al que se le quiere extraer raíz cuadrada y deposite en unas cuantas localidades de la memoria el resultado (la raíz cuadrada), entonces solamente se requieren unas cuantas localidades de la memoria RAM para almacenar el número al que se le extraerá la raíz cuadrada, y unas cuantas localidades de la memoria RAM para depositar el resultado (para almacenar la respuesta se pueden usar las mismas localidades de la memoria en las que estaba puesto el número al que se le iba a extraer la raíz cuadrada al no ser ya necesario conservar el número original).
No es posible obtener, en un solo paso único, la raíz cuadrada de un número cualquiera, puesto que no es una operación elemental como la operación de adición que se puede realizar en una computadora mediante el bloque sumador completo (que forma parte de la unidad de aritmética y lógica ALU), bastando con poner a la entrada del sumador completo los dos números a ser sumados y dejar que la lógica combinatórica produzca la respuesta a la salida del sumador completo.
En el análisis comparativo de las metodologías RISC y CISC que se llevó a cabo arriba en donde se supuso la existencia de un comando PROD para llevar a cabo el producto de dos números, no se entró en mayores detalles sobre cómo se pueda llevar a cabo tal operación aritmética, la cual vista en mayor detalle no parece ser una operación elemental que se pueda efectuar en un solo paso. Repasemos la manera usual en la cual se lleva a cabo a mano el producto de los dos números 285 y 774 (siguiendo la costumbre escolar, el menor de los números será tomado como el multiplicador y el mayor de los números será tomado como multiplicando):

La razón por la cual el método escolar siempre funciona puede verse mejor descomponiendo el multiplicando (285) en una suma de unidades, decenas y centenas:
285 = 2×100 + 8×10 + 5×1
De este modo, la operación de multiplicación viene siendo:
774 × 285 = 774 × (2×100 + 8×10 + 5)Este ejemplo sencillo nos ilustra que los productos parciales en una operación de multiplicación en realidad tienen a su derecha (con la excepción del primer producto parcial) uno o varios ceros que usualmente no se ponen “porque se sobreentienden” (desafortunadamente, lo que puede ser claro para el maestro no necesariamente es claro para todos los alumnos que tienen la obligación de aprenderse muchos procedimientos mecánicos a los cuales no se les dá mucha justificación), con lo cual la operación de multiplicación en realidad debería escribirse del siguiente modo:
774 × 285 = 774×2×100 + 774×8×10 + 774×5
774 × 285 = (774×2)×100 + (774×8)×10 + 774×5
774 × 285 = (774×2)×100 + (774×8)×10 + 774×5
774 × 285 = (1548)×100 + (6192)×10 + 774×5
774 × 285 = 154800 + 61920 + 3870
774 × 285 = 220590

Tomando como paradigma el procedimiento escolar clásico para llevar a cabo la multiplicación de dos números en sistema decimal, podemos delinear la manera en la cual se puede llevar a cabo la multiplicación de dos números en el sistema binario, que es el sistema aritmético propio de las computadoras digitales. El equivalente en sistema binario del número decimal 285 es 100011101, mientras que el equivalente en sistema binario del número decimal 774 es 1100000110. De este modo, la multiplicación llevando a cabo la suma de los productos parciales toma el siguiente aspecto:

aunque como ya se dijo, eliminando los “sobreentendidos” (que en muchas ocasiones son la causa de confusiones que se van arrastrando de por vida) la multiplicación binaria debe ser tomada como:

Si llevamos a cabo la conversión del resultado 110101110110101110 al sistema decimal, encontramos que el producto de los dos números binarios es igual a 220590, el mismo resultado que el que se obtendría si se lleva a cabo la multiplicación en sistema decimal.
El método “clásico” para llevar a cabo el producto de dos números, ya sea en sistema decimal o en sistema binario, requiere forzosamente de la evaluación de varios productos parciales, los cuales deben ser sumados para dar el resultado final. En pocas palabras, se requiere no de uno sino de varios pasos para poder obtener el producto de dos números. Y todo aquello que requiera no de uno sino de varios pasos para ser completado necesariamente se tiene que llevar a cabo usando lógica secuencial, no lógica combinatórica. Mientras que una operación que se pueda llevar a cabo en un solo paso (como una adición binaria) requiere de un solo “ciclo de reloj”, una operación que requiera de una cantidad n de pasos requerirá de n “ciclos de reloj”. ¿Significa ésto que no hay manera en la cual el producto binario de dos números no pueda llevarse a cabo usando lógica combinatórica, esto es, requiriendo de un solo “ciclo de reloj”? No necesariamente. Veamos primero lo que se requiere para obtener en una computadora digital el producto de los números 642 y 375, el cual es igual a 240750:

Para que se pueda efectuar el producto de ambos números recurriendo a lógica combinatórica, se requiere de la existencia de algún bloque que llamaremos PROD en el cual con el solo hecho de meterle a su entrada los dos números a ser multiplicados, y sin necesidad de tener que hacer algo más, se producirá una salida que es igual al producto de ambos números:
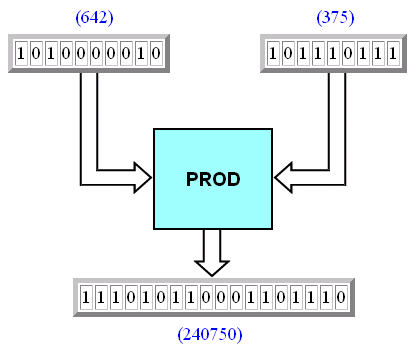
Para simplificar las cosas, consideraremos una máquina en la cual los números a ser multiplicados pueden ser números de cinco bits, y usaremos como ejemplo los números 11 y 15, cuyos equivalentes binarios son 1011 y 1111. Llevando a cabo la multiplicación en sistema binario, vemos que:

Al trabajar en sistema binario, tenemos algo a nuestro favor, y ello es el hecho de que todos los productos parciales o son iguales al multiplicando si el dígito multiplicador es un uno (“1”) con una cantidad de ceros añadidos a su derecha de acuerdo a la posición del dígito en el multiplicador, o son iguales a puros ceros si el dígito multiplicador es un cero (“0”). Esto significa que podemos usar cada dígito del multiplicador como una máscara para dejar “pasar” intacto al multiplicando cuando el dígito del multiplicador es “1”, agregando los ceros que se requieran a la derecha del producto parcial, o bloquear por completo el multiplicando poniendo todos sus dígitos a cero cuando el dígito multiplicador es “0”, lo cual se puede efectuar mediante compuertas lógicas. En la siguiente ilustración tenemos el esquema sobre cómo funcionaría ésto (obsérvese que cuando el dígito del multiplicador es un “1”, la compuerta lógica en el extremo derecho del registro intermedio se pone de color verde indicando con ello que la compuerta se abre dejando pasar intacto al multiplicando al lugar que le corresponde como producto parcial; mientras que cuando el dígito del multiplicador es un “0” la compuerta lógica en el extremo derecho del registro intermedio se pone de color rojo indicando con ello que la compuerta se cierra no dejando pasar ningún dígito del multiplicando, lo cual equivale a poner el producto parcial correspondiente en ceros):

Mediante este esquema, basta con poner los dos números a ser multiplicados a la entrada para obtener en forma casi instantánea a la salida, en un solo “ciclo de reloj”, el producto de dichos números, usando pura lógica combinatórica. Este esquema puede funcionar. A continuación se tiene lo mismo, pero llevando a cabo la multiplicación de otros dos números decimales, 18 y 25, o lo que es lo mismo, la multiplicación de los números binarios 10010 y 11001 al nivel del lenguaje de máquina:

¿Y qué del caso cuando los dos números de cuatro bits a ser multiplicados son lo máximo posible, con los registros de cuatro repletos a toda su capacidad con “1”? Puesto que el número binario 11111 equivale al número decimal 31, el producto de dicho número por sí mismo es igual a 961, cuyo equivalente binario es 1111000001. Pero este número excede la capacidad del registro en el que se deposita el resultado del producto de los dos números binarios de cuatro bits, porque ese registro solo tiene capacidad para nueve bits, no para diez. Lo que se puede hacer en todo caso es añadir un registro adicional con el que se pueda interpretar el bit que ya no cabo (el bit más significativo) considerándolo como un bit de sobreflujo, con lo cual podemos completar el diseño de nuestro bloque lógico PROD del modo siguiente:

Desde el punto de vista del hardware, para multiplicar dos números binarios pequeños de tan solo cuatro bits de extensión cada uno se requiere de cinco registros (A,B,C,D,E) de nueve bits de capacidad cada uno para poder almacenar los productos parciales, se requiere además de de cinco compuertas lógicas conectadas al registro en el cual será puesto el multiplicador, y encima de todo ello se requiere de un sumador binario que sea capaz de tomar en su entrada no dos sino cinco sumandos. Para esto último podemos construír un sumador completo de cinco sumandos binarios conectando en cascada varios bloques de sumación completa:

aunque se puede intentar llevar a cabo un diseño óptimo mínimo poniendo a dura prueba los métodos de minimización para circuitos lógicos combinatóricos. Resulta ahora evidente que para un bloque PROD que sea capaz de multiplicar dos números de 16 bits cada uno en un solo paso mediante pura lógica combinatórica, el esquema será considerablemente más complejo. Aún en estos tiempos en los que gracias a la litografía de la microelectrónica podemos agregar una porción de adicional de lógica a un circuito integrado que consuma varias decenas de miles de transistores, un bloque PROD como el que se ha descrito representa un aumento considerable en la complejidad del diseño de un procesador CPU que se antoja indesable incluso para los más entusiastas promotores de la filosofía CISC.
La alternativa al bloque PROD, desde luego, es desechar la idea de construír un bloque PROD que lleve a cabo la multiplicación en un solo “ciclo de reloj” de dos números mediante lógica combinatórica, y recurrir a un diseño en el que mediante varios pasos (haciendo uso intensivo de un registro de transferencia, también conocido como registro de corrimiento o registro de desplazamiento) y usando un solo sumador completo y un solo acumulador se pueda obtener el mismo resultado, pero pagando el costo del tiempo adicional que requerirá un algoritmo de varios pasos. En lo que respecta al sumador completo, si vamos sumando los productos parciales A, B, C, D y E de dos en dos, el procedimiento de suma cumulativa se puede llevar a cabo del siguiente modo obteniéndose la respuesta final en una variable intermedia que llamaremos Z:
Paso # 1: W = A + BAquí es en donde puede entrar una duda: ¿acaso no es parte de la filosofía RISC el tratar de llevar a cabo todo en un solo “ciclo de reloj” en lugar de llevarlo a cabo en un proceso multi-ciclo? La alternativa de varios pasos sigue siendo RISC, ya que cada uno de los pasos implementados mediante lógica secuencial para obtener el equivalente del comando PROD requiere, individualmente, de un solo “ciclo de reloj”. El uso de lógica secuencial transfiere la carga de una complejidad mayor en el hardware a una complejidad mayor en la elaboración del programa que lleve a cabo el procedimiento de multiplicación binaria, consumiendo más memoria RAM para el almacenamiento de esos pasos adicionales. Aquí es en donde entra de nuevo la disyuntiva del diseño RISC y el diseño CISC. En un diseño CISC, sin consideración alguna al aumento en la complejidad del circuito integrado, lo natural es agregarle un bloque PROD al procesador para que pueda llevar a cabo la multiplicación de dos números, pagando un costo en el aumento en la complejidad del procesador; mientras que en un diseño RISC se desecha por completo la idea de meterle al procesador cientos de miles de transistores adicionales y se acepta la idea de compensar la ausencia de un bloque PROD recurriendo a un número de operaciones elementales, invirtiendo para ello más espacio en la memoria RAM que será requerido por cualquier programa que haga uso de la operación de multiplicación.
Paso # 2: X = C + W
Paso # 3: Y = D + X
Paso # 4: Z = Y + E
A la luz de todo lo que hemos visto, efectivamente con un procesador más complejo podemos ahorrar una buena cantidad de memoria RAM, y podemos simplificar enormemente la naturaleza del programa compilador usado para llevar a cabo operaciones matemáticas laboriosas. Sin embargo, hay que pagar un precio por ello, y el precio se paga en el hardware, en el aumento en la complejidad del diseño del procesador. Se siguen requiriendo de las cien (o más) instrucciones para llevar a cabo la extracción de la raíz cuadrada, en esto no hay simplificación posible, pero esto no se ve porque todas esas instrucciones han sido metidas en el corazón del procesador, han sido codificadas como microinstrucciones en la unidad de control del procesador. ¿Pero qué acaso no se requiere de algún espacio en donde se puedan ir almacenando varios de los resultados intermedios temporales que tienen que ser puestos en algún lado para estar disponibles conforme avance la evaluación numérica? ¿Acaso no se requiere de memoria RAM para esto? La respuesta es negativa, porque como recurso de almacenamiento temporal de resultados intermedios se puede utilizar el espacio disponible en los registros internos del procesador, de forma tal que lo que antes era una serie intensiva de transacciones entre la unidad de ejecución (el procesador) y la memoria RAM ahora se ha convertido en una serie intensiva de transacciones entre la unidad de ejecución y los registros usados internamente por el procesador. Uso de registros internos en lugar de memoria RAM es parte de la filosofía de los procesadores CISC.
Puesto que una instrucción en lenguaje de máquina de una operación elaborada como la extracción de una raíz cuadrada requiere de la ejecución de varias (muchas) operaciones de cómputo elementales, tal operación no se puede llevar a cabo en un solo “ciclo de reloj”, se requiere de muchos ciclos internos. Y basta con meter al conjunto de instrucciones de un procesador una sola instrucción cuyo tiempo de ejecución sea considerablemente mayor que cualquiera de las demás instrucciones para que cualquier aspiración de implementar técnicas de multiprocesamiento de instrucciones basadas en la técnica del pipelining que ser abandonada.
Un parámetro que en ocasiones es utilizado para identificar a un procesador como procesador CISC es la inclusión en su arquitectura de registros para propósitos especiales, tales como registros para puntero de la pila, manejo de interrupciones, etcétera. La inclusión de estos registros adicionales puede simplificar algo el diseño del hardware, pero al costo de hacer que el conjunto de instrucciones sea más complejo. Otro parámetro que en ocasiones también es utilizado para identificar a un procesador como procesador CISC es la inclusión en su arquitectura del registro llamado “registro de códigos de condición”, el cual refleja si el resultado de la última operación llevada a cabo es menor que, igual, o mayor que cero, y registra también si han ocurrido algunas condiciones de error. Bajo este criterio, un procesador como el microprocesador Motorola 6809 sería clasificado como procesador CISC porque incorpora este tipo de registro. Sin embargo, es necesario inspeccionar todo el conjunto de instrucciones del procesador para poder tener una idea del sitio que le corresponde.
La siguiente ecuación, conocida como la ecuación de desempeño, es frecuentemente usada para expresar la capacidad de desempeño de una computadora:

La metodología CISC intenta minimizar el número de instrucciones por programa (con instrucciones complejas como MULT), pero a costa de aumentar el número de ciclos por instrucción. La metodología RISC hace lo contrario, disminuyendo los ciclos por instrucción al evitar incluír en su conjunto de instrucciones tipo RISC algo como la instrucción compleja MULT, pero al costo de aumentar el número de instrucciones por programa (haciendo uso intensivo de instrucciones como LOAD y STORE).
Pese a las ventajas del procesamiento RISC, los circuitos integrados RISC tomaron más de una década para empezar a ser tomados en serio en el mundo comercial. Esto fue debido en gran parte a la ausencia de apoyo de software.
Aunque la línea de computadoras de Apple conocidas como Power Macintosh empleaba chips basados en RISC, y pese a que el sistema operativo Windows NT de Microsoft era compatible con computadoras basadas en RISC, la interfaz gráfica Windows 3.1 y el primer sistema operativo Windows 95 para amplio uso en computadoras domésticas fueron elaborados teniendo en mente los procesadores CISC producidos por Intel. Muchas compañías no estaban dispuestas a tomar riesgos con la tecnología RISC emergente, y los fabricantes de microprocesadores no estaban dispuestos a fabricar circuitos integrados RISC en volúmenes lo suficientemente grandes para hacer sus precios competitivos. Otro causa de retroceso fue debido a la presencia y predominancia de Intel. Aunque sus circuitos integrados CISC se estaban volviendo cada vez más difíciles de desarrollar, Intel tenía los recursos económicos necesarios para solventar las dificultades y así continuar produciendo procesadores poderosos. Aunque los chips RISC pudieran superar los esfuerzos de Intel en áreas específicas, las diferencias no fueron lo suficientemente grandes como para persuadir a los compradores para hacer un cambio de tecnologías.
Un factor a favor de la tecnología RISC es la caída en los precios de la memoria. En 1977, 1 Megabyte de memoria dinámica DRAM costaba alrededor de 5 mil dólares. Para 1994, la misma cantidad de memoria tenía un precio de únicamente 6 dólares (ajustes hechos para tomar en cuenta la inflación). La dramática caída en los precios de la memoria RAM disminuye la presión por la construcción de procesadores complejos que puedan hacer lo más que se pueda con una cantidad muy limitada de memoria. Al mismo tiempo, los avances en la tecnología de construcción de computadoras ha estado produciendo compiladores más sofisticados que son capaces de hacer mejor uso de los procesadores RISC, lo cual ha aumentado la presión sobre los procesadores CISC.
Quizá una manera posible de saber si cierta arquitectura es una arquitectura RISC O CISC consista en ver la cantidad de instrucciones que forman parte del conjunto de instrucciones del diseño, aunque al inicio del tercer milenio este parámetro no era muy confiable (y de hecho no es confiable). Si una computadora contiene un procesador que tiene disponibles 60 instrucciones, podemos suponer que se trata de una computadora RISC y que no tiene más de lo estrictamente necesario para realizar labores de cómputo, con operaciones de cómputo complejas teniendo que ser llevadas a cabo por programas que sean capaces de poder manejar muchas combinaciones de instrucciones elementales. Pero si la máquina tiene disponibles 500 instrucciones en su conjunto de instrucciones, podemos suponer que se trata de una computadora CISC.
Entre mayor sea el número de instrucciones disponibles en el conjunto de instrucciones de un procesador esto implicará que el ensamblador usado para ensamblar programas en lenguaje de máquina para dicho procesador tendrá que ser más grande requiriendo de una mayor cantidad de memoria RAM para poder llevar a cabo el ensamble con la capacidad de poder incluír todas las instrucciones disponibles en el repertorio del procesador, pudiendo decirse lo mismo de un programa interpretador o de un programa compilador. Y entre más voluminoso y complejo sea un programa ensamblador o un programa compilador para convertir instrucciones a lenguaje de máquina, tanto mayor tendrá que ser su costo de elaboración. En pocas palabras, el uso de un procesador CISC trae consigo un costo oculto. En un caso extremo, un procesador CISC cuyo conjunto de instrucciones contenga unas 20 mil instrucciones disponibles en lenguaje de máquina posiblemente será tan complejo que, aún con los recursos actuales, ninguna empresa podrá construír un ensamblador o un compilador que sea capaz de poder darle entrada al manejo de tan amplia variedad de instrucciones garantizando que lo hará optimizando recursos (esto es, seleccionando subconjuntos de instrucciones con los cuales se pueda hacer lo mismo pero con la menor cantidad de código ejecutable), ni será humanamente posible el poder visualizar la mejor manera de elaborar programas de aplicación seleccionando el subconjunto de instrucciones que resulten en un programa de aplicación lo más pequeño posible (y por lo tanto lo más rápido posible) para tal procesador.
Otra manera de poder apreciar la distinción entre la filosofía RISC y la filosofía CISC consiste en ver la evolución de los primeros procesadores CPU fabricados por la empresa Intel y la aparición de sus parejas complementarias, los coprocesadores matemáticos.
Las computadoras digitales por su propia naturaleza hacen operaciones aritméticas con números enteros, no llevan a cabo aritmética de punto flotante incorporando el punto decimal. Se les puede programar para que lleven a cabo operaciones aritméticas tales como multiplicar 25.737 por 74.58, pero para ello hay que hacer las conversiones necesarias mediante alguna programación para que los números con punto decimal sean convertidos a números enteros que serán manipulados por la computadora, y una vez que se obtengan los resultados se lleve a cabo la operación inversa, convirtiendo el resultado obtenido en números enteros a números con punto decimal.
Quienes posean o hayan poseído alguna calculadora con funciones científicas para el cálculo de funciones matemáticas tales como las funciones trigonométricas seno y coseno o como las funciones exponenciales o logarítmicas, tal vez se les haya ocurrido algo sobre la conveniencia de “conectar” de alguna manera una computadora digital a una calculadora científica para sacar el máximo provecho de ambos mundos (de hecho, una calculadora científica contiene una unidad de procesamiento central y un conjunto especializado de instrucciones para la evaluación de funciones matemáticas):

Precisamente con esto en mente, cuando hizo su aparición el procesador Intel 8086 al poco tiempo se introdujo un coprocesador matemático, el 8087. La adición física del coprocesador matemático 8087 a la tarjeta madre interna de la computadora (suponiendo que en la tarjeta madre del modelo de máquina tuviera un socket receptor diseñado para la inserción del coprocesador matemático, algunos modelos no tenían dicho socket) aumentaba en forma garantizada la rapidez de la máquina para la ejecución de cálculos matemáticos en la aritmética de punto flotante. Posteriormente, con la introducción del procesador 80286, la empresa Intel también introdujo por separado como complemento optativo el coprocesador matemático 80287 diseñado para formar un par con el 80286. Podemos hablar en efecto de una familia creciente de coprocesadores matemáticos, los coprocesadores matemáticos x87 que hacían par con los microprocesadores x86. El esquema general de un procesador x86 sin el apoyo de un coprocesador matemático x87 es la siguiente:
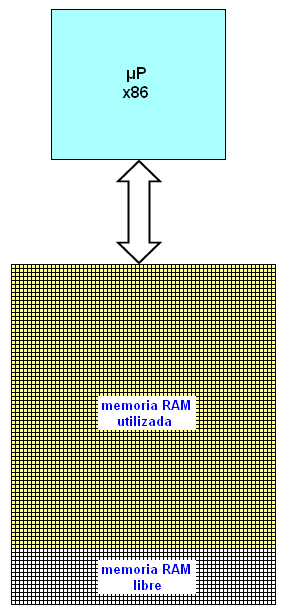
Al ser agregado un coprocesador matemático, la situación cambia del modo siguiente:

Obsérvese cómo un programa ejecutándose en la computadora construída sin el coprocesador matemático consume una cantidad mayor de memoria RAM que la misma computadora a la cual se le ha agregado el coprocesador matemático. Esto se debe a que instrucciones tales como una instrucción para obtener la raíz cuadrada de un número, en vez de consumir una gran cantidad de instrucciones LOAD y STORE que requieren de una mayor cantidad de memoria para el almacenamiento de resultados intermedios, pueden llevar a cabo la extracción de la raíz cuadrada con una sola instrucción como FSQRT (véase en los apéndices el anexo titulado “Los coprocesadores matemáticos”). El conjunto de instrucciones que puede manejar un coprocesador matemático x87 aumenta el conjunto de instrucciones que puede manejar un procesador x86 por sí solo. En el diagrama anterior consideramos al procesador y al coprocesador como dos componentes separados. Sin embargo, si juntamos ambos componentes en un solo circuito integrado, de modo tal que en vez de tener en la tablilla de electrónica dos circuitos integrados tengamos uno solo, una especie de “macro”-procesador, podemos ver de inmediato que la electrónica de tal “macro”-procesador será indudablemente más compleja que la del procesador x86 por sí solo. Pero resulta que Intel hizo precisamente tal cosa, juntó ambos procesador y coprocesador en un solo componente, al permitirle los avances en la litografía de la microelectrónica llevar a cabo tal fusión, teniéndose de este modo un solo procesador pero con un conjunto ampliado (rebosante incluso) de instrucciones. Esta es precisamente la filosofía de diseño CISC.
Eventualmente, toda la microelectrónica que iba aparejada a los coprocesadores matemáticos terminó siendo incorporada a la microelectrónica del mismo procesador, eliminándose la necesidad de tener que adquirir coprocesadores matemáticos. Lo que no cambió fue el hecho de que la disponibilidad de coprocesadores matemáticos así como su eventual incorporación al procesador central se tradujo en una ampliación del conjunto de instrucciones básico para los procesadores fabricados por Intel. En los apéndices puestos al final de esta obra se encuentra un anexo titulado “Los coprocesasdores matemáticos” en donde podemos ver las instrucciones adicionales que terminaron siendo incorporadas al conjunto básico de procesadores Intel cuando se tiene instalado en la tarjeta madre de la computadora un coprocesador de matemáticas. Con la ayuda de un programa ensamblador como Turbo Assembler que reconozca todas las instrucciones que se puedan ejecutar en un procesador Intel al cual se le haya agregado como pareja un coprocesador matemático, podemos escribir instrucciones que incorporen mnemónicas tales como FYL2X (logaritmo base dos de un número), FSQRT (extracción de la raíz cuadrada de un número real) y FLDPI (la constante matemática π).
Veamos ahora algunas instrucciones para los procesadores Intel que no son (propiamente dicho) universales para todos los procesadores fabricados por dicha empresa, esto es, no forman parte del conjunto básico, y por lo tanto no todas las familias de procesadores x86 pueden ejecutar dichas instrucciones al no formar parte del conjunto que pueden reconocer:
| Código Op (hex) | Instrucción | 8086 | 80286 | 80386 |
| 37 |
AAA
ASCII Adjust after Addition | √ | √ | √ |
| D5 0A |
AAD
ASCII Adjust AX before division | √ | √ | √ |
| D4 0A |
AAM
ASCII Adjust AX after Multiply | √ | √ | √ |
| 3F |
AAS
ASCII Adjust AL after Subraction | √ | √ | √ |
| 63 |
ARPL
Adjust RPL field of selector | √ | √ | |
| 62 |
BOUND
Check array index against Bounds | √ | √ | |
| 0F BC |
BSF
Bit scan forward | √ | ||
| 0F BD |
BSR
Bit Scan Reverse | √ | ||
| 0F A3 |
BT
Bit Test | √ | ||
| 0F BB |
BTC
Bit Test and Complement | √ | ||
| 0F B3 |
BTR
Bit Test and Reset | √ | ||
| 0F AB |
BTS
Bit Test and Set | √ | ||
| 98 |
CBW
Convert Byte to Word | √ | √ | √ |
| 99 |
CDQ
Convert Doubleword to Quadword | √ | ||
| 0F 06 |
CLTS
Clear Task Switched flag | √ | √ | |
| 98 |
CWDE
Convert byte to Doubleword | √ | ||
| F6 F7 |
DIV
Unsigned Divide | √ | ||
| C8 |
ENTER
Make stack frame for procedure parameters | √ | √ | |
| CF |
IRETD
Interrupt Return | √ | √ | |
| 0F 02 |
LAR
Load Access Rights byte | √ | √ | |
| C9 |
LEAVE
High level procedure exit | √ | √ | |
| 0F 01 |
LMSW
Load Machine Status Word | √ | √ | |
| F0 |
LOCK
Assert LOCK# signal prefix | √ | √ | √ |
| 0F 03 |
LSL
Load Segment Limit | √ | √ | |
| 0F 00 |
LTR
Load Task Register | √ | √ | |
| 61 |
POPAD
Pop All general registers | √ | ||
| 9D |
POPFD
Pop from stack into EFLAGS | √ | ||
| 60 |
PUSHAD
Push All general registers | √ | ||
| 9C |
PUSHFD
Push Flags register onto the stack | √ | ||
| AF |
SCASD
Compare String data | √ | ||
| 0F 01 |
SGDT/SIDT
Store Global/Interrupt Descriptor Table | √ | √ | |
| 0F A4 0F A5 |
SHLD
Double precision Shift Left | √ | ||
| 0F AC 0F AD |
SHRD
Double precision Shift Right | √ | ||
| 0F 00 |
SLDT
Store local descriptor table | √ | √ | |
| 0F 01 |
SMSW
Store Machine Status Word | √ | √ |
Un programa que use estas instrucciones podrá ser ejecutado en cualquier computadora que use el procesador Intel 80386, pero no necesariamente podrá ser ejecutado en máquinas que usen un procesador 8086. De hecho, de las instrucciones dadas arriba, únicamente las instrucciones AAA, AAD, AAM, AAS, CBW y LOCK podrán ser llevadas a cabo por todos los procesadores listados. Y dependiendo de las instrucciones que sean tomadas de este conjunto de instrucciones, tal vez el programa pueda ser ejecutado en una máquina que use el procesador 80286. En realidad, sólo el que escribe un programa lo sabe a ciencia cierta, y si el programador no es meticuloso, ni siquiera él mismo lo sabrá. Esto revela las dificultades que existen en tratar de mantener una compatibilidad hacia abajo con la introducción de nuevos procesadores que incorporan conjuntos cada vez más amplios y complejos de instrucciones. Las únicas dos opciones para hacer frente a esto son: (1) Hacer que desde un principio y usando el conjunto más básico de todas las instrucciones disponibles el programa detecte el tipo de procesador que está siendo utilizado, y ofrecerle una disculpa al usuario diciéndole que su máquina requiere como mínimo tal o cual procesador; esto es lo que ocurre cuando un programa se rehusa a instalarse en el disco duro de cierta máquina tras verificar los recursos de hardware con los que se cuentan; de aquí vienen los requisitos mínimos de hardware que cada nueva versión del sistema operativo Windows así como de programas de aplicación imponen a los propietarios de máquinas no tan nuevas (por ejemplo, el sistema operativo Windows XP pide como mínimo un procesador del tipo Intel Pentium, y el programa de aplicación Partition Commander 10 pide como mínimo un procesador Intel x86 de 32 bits de capacidad), y (2) integrar en el programa dos (o más, dependiendo qué tanta compatibilidad “hacia atrás” se quiera tener) programas distintos después de que se detecte el tipo de procesador que se está utilizando, y empezar la ejecución (o la instalación) con el programa más adecuado. La segunda opción presenta la desventaja de que se requiere un trabajo doble (o triple, o cuádruple) de parte del programador, lo cual nulifica las ventajas que ofrezca el poseer un conjunto de instrucciones cada vez más elaborado y complejo.
Hablando en términos generales, sin hacer referencia a algún procesador en particular, podemos suponer como algo posible con la tecnología actual el poder diseñar un procesador que tenga una instrucción log disponible en su conjunto de mnemónicas propias de un lenguaje ensamblador, la cual podría ser usada desde el entorno del lenguaje ensamblador con una serie de instrucciones como las siguientes:
mov G, $C5E7
log G
mov $CE7, G
La primera instrucción mov se encargaría de cargar en un registro G con una capacidad de 32 bits un número real (propio de la aritmética de punto flotante) como 76.348, tomado de la memoria a partir del domicilio hexadecimal C5E7; la segunda instrucción log se encargaría de obtener el logaritmo del número real contenido en el registro G, dejando el resultado en el mismo registro; y la tercera instrucción mov se encargaría de depositar en el domicilio de la memoria C5E7 el logaritmo del número que estaba contenido originalmente a partir de dicho domicilio. Puesto que estamos hablando de una instrucción implementada con una mnemónica en lenguaje ensamblador, la implementación de lo anterior se traduciría en tres instrucciones en lenguaje de máquina. ¡Pero un momento! ¿Acaso la evaluación de algo como el logaritmo de un número no requiere una abundante cantidad de instrucciones en lenguaje de máquina implementando una “receta de cocina” en lo que a cuestión de operaciones más elemenentales se refiere (un algoritmo), usando de manera intensiva operaciones más sencillas como carga de bytes de la memoria al procesador, adiciones, substracciones, comparaciones, y almacenamientos del procesador a la memoria? ¿Cómo es posible entonces que una sola instrucción pueda reemplazar todo eso? ¿En dónde están todas esas instrucciones requeridas para hacer tantas cosas con una sola instrucción disponible en el repertorio de instrucciones del procesador? La respuesta es: dentro del mismo procesador, y para mayor detalle, dentro de la unidad de control del procesador. En efecto, se trata de una serie prolija de microinstrucciones que hacen posible crear a nivel de lenguaje de máquina una instrucción tan sofisticada (hablando en términos numéricos) como log. Este conjunto de microinstrucciones es completamente invisible tanto para el programador de sistemas como para el diseñista de computadoras digitales con algún propósito específico. La microprogramación del procesador es algo que compete única y exclusivamente al diseñista del mismo microprocesador, y una vez que se ha llevado a cabo la microprogramación de la unidad de control, no hay corrección posible puesto que la secuencia de pasos requeridas en una microprogramación queda grabada permanentemente en la litografía del circuito integrado, en la misma electrónica del compomente.
Sin lugar a dudas, la ampliación del conjunto de instrucciones de una computadora para incluír instrucciones a nivel de lenguaje de máquina tan sofisticadas como la instrucción log para la evaluación del logaritmo de un número real trae consigo un aumento en la velocidad con la cual se puedan ejecutar programas de índole científica, en contraste con la alternativa de que la implementación de tales funciones se tenga que llevar a cabo mediante algoritmos y subrutinas almacenadas en la memoria RAM usada por el procesador. ¿Pero de qué tanta mejora estamos hablando?
Para quienes se ganan la vida escribiendo compiladores, entre más grandes sean los conjuntos de instrucciones elaborados para una familia de procesadores y entre más complejas sean las funciones que implementen, tanto mejor porque lo que de otra manera tendrían que implementar por medio de software recurriendo a cosas que terminan convirtiéndose en cientos o miles de instrucciones en lenguaje de máquina se le puede relegar a la máquina con instrucciones invocables inclusive a nivel de lenguaje ensamblador. Tómese por ejemplo el caso en el cual se quiera tener disponible en todo momento la capacidad para poder elaborar funciones de Bessel de primer orden. A nivel de software, esto requiere procurar librerías especializadas en funciones matemáticas que puedan ser invocadas como subrutinas por algún programa especializado, y el código fuente contendrá alguna línea que diga algo como BESSEL1(N), la cual al ser compilada terminará convirtiéndose en cientos o quizá miles de instrucciones en lenguaje de máquina. Pero si dentro de lo que puede manejar el procesador hay alguna instrucción cuya mnemnónica en assembler es algo así como bessel1, entonces el constructor del compilador solo tiene que invocar dicha instrucción con una sola línea en su programa compilador. Ciertamente, parece haber una ventaja en ir aumentando en cada familia sucesiva de procesadores su disponibilidad de instrucciones. Además, es bien sabido que las instrucciones que se implementan por la vía del hardware bajo la dirección de la unidad de control del CPU son procesadas de modo más rápido que si son implementadas por la vía de software almacenado en la memoria RAM de la computadora.
El conjunto de microinstrucciones que se le pueden agregar a la unidad de control de un procesador puede ser tan sofisticado que incluso es posible implementar un lenguaje completo de programación a nivel de hardware (se citará a modo de ejemplo el libro Microprogrammed APL Implementation of APL de Rodnay Zaks).
Sin embargo, irle aumentando el número de instrucciones al conjunto de instrucciones que pueda manejar un procesador trae un costo terrible: el microprograma implementado por la unidad de control del CPU se va haciendo horriblemente complicado. Y la fría realidad es que ultimadamente las instrucciones cada vez más complejas que se van incorporando a un procesador recurren casi siempre al uso intensivo de operaciones sencillas tales como load (carga) y store (almacenar) junto con operaciones elementales de suma, resta, multiplicación y división, e inclusive las operaciones de multiplicación y división se apoyan en simples operaciones de desplazamientos shift y adiciones. Hasta la misma resta es simplificada mediante la aritmética de dos complemento. Si recurrimos a las especificaciones del fabricante y echamos un vistazo al número de “pulsos de reloj” que requiere un procesador 8086 para ejecutar una instrucción de add (suma) encontramos que solo requiere de cuatro pulsos de reloj. En cambio, si echamos un vistazo al número de “pulsos de reloj” que requiere una operación fsqrt de extracción de raíz cuadrada con la ayuda del coprocesador matemático 8087, encontramos que se requieren de 180 a 186 “pulsos de reloj”, lo cual se traduce en un aumento en el tiempo de ejecución que no es significativamente menor que el tiempo que requiere llevar a cabo lo mismo a nivel de software usando algún algoritmo (receta de cocina) para el cálculo de la raíz cuadrada.
La microprogramación de la unidad de control (que constituye en esencia lo que se conoce como lógica programada) es conocida como firmware en virtud de que, una vez que se han incorporado las funciones avanzadas que se pretenden llevar a cabo, al ser producida la litografía del circuito integrado ya no es posible dar marcha atrás para corregir errores, la lógica está grabada firmemente en la electrónica del circuito integrado. Esta microprogramación se puede llevar a cabo recurriendo a bloques lógicos conocidos como arreglos lógicos programables o PLA (Programmable Logic Array), los cuales son parte de la misma arquitectura del procesador al ser parte de la unidad de control del procesador.
Se podría argumentar que ni siquiera empresas tan acaudaladas como Intel y AMD, inclusive juntando recursos, se atreverían a emprender un proyecto como el diseñar y fabricar un macro-procesador (ya no se le podría llamar microprocesador, ni siquiera procesador) capaz de poseer un conjunto de unas 20 mil instrucciones en lenguaje de máquina, al menos no con la tecnología actual. Un proyecto de esta envergadura sería considerado poco menos que una imposibilidad tecnológica. Pero apenas hace unos cuantos años la sola posibilidad de que se pudieran fabricar dispositivos portátiles de memoria USB capaces de acarrear 64 gigabytes de información habría sido considerada una locura. Y si a los científicos que diseñaron y construyeron la primera computadora electrónica ENIAC alguien les hubiera dicho que llegaría el día en que la computadora que les costó tanto trabajo construír y que ocupaba tanto espacio sería reemplazada por computadoras cientos de veces más poderosas pero capaces de caber en una mano, y con un costo de unos cuantos cientos de dólares, posiblemente lo habrían tomado como un chiste y algunos tal vez se habrían muerto de la risa; aunque de seguro trayendo a cualquiera de los pioneros de las ciencias computacionales de aquél entonces a nuestros tiempos actuales con un túnel del tiempo todos ellos se quedarían estupefactos con la boca abierta. El debate acerca de las ventajas y beneficios de las arquitecturas RISC y CISC así como sus desventajas se ha mantenido en su mayor parte en los ámbitos académicos en virtud de que el número de instrucciones de los procesadores CISC no se considerablemente mayor que el número de instrucciones de los procesadores RISC, haciendo que ambas arquitecturas convivan en una zona nebulosa en la cual hay incluso un traslape. Pero al aumentar la brecha, la discusión necesariamente tiene que dejar de ser académica, y los avances futuros posiblemente deberán estar basados más en la búsqueda de nuevas tecnologías o conceptos teóricos de vanguardia que en irle poniendo más y más componentes lógicos a la misma pieza de silicio. En el pasado, la motivación principal para construír máquinas con procesadores que implementaran conjuntos de instrucciones cada vez más más grandes era el elevadísimo precio de las memorias RAM, pero esta ventaja a favor de la arquitectura CISC se ha ido evaporando gracias a los avances en la tecnología de las memorias de estado sólido.
Aunque la diferencia clara que había entre los procesadores RISC y CISC se ha ido volviendo cada vez más borrosa al empezar a absorber los procesadores RISC parte de las ventajas que ofrece el procesamiento CISC y al empezar a absorber los procesadores CISC parte de las ventajas que ofrece el procesamiento RISC, hay ejemplos de procesadores en los cuales su arquitectura parece marcar la diferencia A continuación se dan algunos ejemplos de procesadores CISC (algunos de los cuales son únicamente de importancia histórica) entre los muchos ejemplos que podrían citarse:
1. La computadora IBM 370/168. Introducida en 1970, este diseño CISC era un procesador de 32 bits con 4 registros de propósito general y 4 registros de 64 bits para aritmética de punto flotante.
2. La computadora VAX 11/780. Esta máquina fabricada por DEC (Digital Equipment Corporation) usaba un procesador de 32 bits y daba apoyo a un gran número de modos de domiciliamiento e instrucciones en lenguaje de máquina.
3. El microprocesador Intel 80486. Lanzado en 1989, este procesador CISC poseía ya instrucciones con longitudes que variaban de 1 a 11 bits, y tenía 235 instrucciones. Este procesador fijó la tendencia hacia la complejidad CISC adoptada por Intel y por su principal competidor AMD para no quedarse atrás.
A continuación se dan algunos ejemplos de procesadores RISC (algunos de los cuales son únicamente de importancia histórica al cerrar las empresas que les dieron origen):
1. DEC Alpha, de la empresa Digital Equipment Corporation. Originalmente conocido como Alpha AXP, este procesador empleaba una arquitectura con un conjunto reducido de instrucciones RISC de 64 bits diseñado para reemplazar el conjunto complejo de instrucciones CISC de las computadoras VAX de 32 bits fabricadas por la misma empresa.
2. Advanced Micro Devices 29000, de la empresa Advanced Micro Devices (AMD), conocido simplemente como el 29k, perteneció a una familia de microprocesadores y microcontroladores RISC de 32 bits desarrollados y fabricados por AMD. Por algún tiempo, fueron los procesadores RISC más populares en el mercado, usados ampliamente por una variedad de fabricantes para la construcción de impresoras láser.
3. Advanced RISC Machine (ARM). Un procesador RISC de 32 bits desarrollado por la empresa ARM Holdings, previamente conocido como Advanced RISC Machine, y antes de ello como el Acorn RISC Machine. En términos de cantidades producidas, esta arquitectura de 32 bits fue una de las más ampliamente utilizadas, y su simplicidad condujo a su uso amplio en aplicaciones de potencia moderada tales como dispositivos móviles.
4. Atmel AVR. Desarrollado por la empresa Atmel en 1996, este procesador era un microcontrolador (µC) de 8 bits basado en un tipo de arquitectura conocida como arquitectura Harvard. Fue una de las primeras familias de microcontroladores que usaron memoria flash puesta en el mismo circuito integrado para el almacenamiento de programas.
5. MIPS (Microprocesor without Intelocked Pipeline Stages). Desarrollado por la empresa MIPS Computer Systems. Disponible en dos implementaciones, la implementación MIPSS32 de 32 bits, y la implementación MIPS64 de 64 bits,
6. PA-RISC (Precision Architecture - Reduced Instruction Set Computer). Desarrollado por la empresa Hewlett-Packard, fue reemplazado por el procesador Itanium (originalmente IA-64) desarrollado en forma conjunta por Hewlett-Packard e Intel.
7. POWER-PC (Performance Optimization With Enhanced RISC-Performance Computing). Esta es una arquitectura que resultó de una alianza conformada por Apple, IBM y Motorola (AIM). Originalmente diseñado para computadoras domésticas, es usado en procesadores de alto desempeño.
8. SuperH. De la empresa Hitachi, este procesador es implementado por microcontroladores y microprocesadores para sistemas incrustados. Sus principales versiones son SH1, SH2, SH3 y SH4, encontrando usos en una variedad de aplicaciones.
9. SPARC (Scalable Processor Architecture). Este procesador introducido en 1986 fue desarrollado por Sun Microsystems, la misma empresa que desarrolló el lenguaje orientado a objetos bautizado como Java.
De cualquier modo, ha habido avances continuos utilizados tanto por los procesadores RISC como por los procesadores CISC que ha traído como consecuencia que la demarcación entre ambas arquitecturas se haya ido difuminando. De hecho, las dos arquitecturas parecen haber estado adoptando las estrategias del contrario. En virtud de que las velocidades de los procesadores ha ido en aumento, los procesadores CISC son capaces de poder ejecutar más de una instrucción en el lapso de un solo ciclo de reloj, lo cual ha permitido que los chips CISC puedan hacer uso de la técnica de pipelining. Del mismo modo, en virtud de que los avances en la tecnología han hecho posible ir metiendo más transistores en un mismo circuito integrado, los procesadores RISC pueden aprovechar ventajosamente un hardware más complejo para incorporar en sus conjuntos de instrucciones comandos más complicados tipo-CISC.
De este modo, se está presenciando la alborada de una era “post-RISC/CISC” en la cual ambas filosofías se van aproximando la una a la otra, con una convergencia cada vez mayor. Una nueva arquitectura llamada EPIC (Explicitly Parallel Instruction Computing) fue lanzada al inicio del tercer milenio, incorporando las ventajas tanto de RISC como de CISC. Un ejemplo sobresaliente de la filosofía EPIC se encuentra en el procesador Itanium, usado comercialmente en gran escala por gigantes corporativos tales como HP-Compaq y Unisys.
Las circuntancias actuales y el soporte pesado recibido de Intel han contribuído a que el diseño CISC comparta la mayor parte del mercado de computación inteligente. Sin embargo RISC, en virtud de sus métodos eficientes ha hecho un progreso rápido en dispositivos manuales y portátiles, de los cuales el Nintendo DS y el Apple iPod son ejemplos prominentes, garantizando con ello que ambas filosofías tengan garantizados sus nichos con amplios futuros a menos de que evolucione algún otro diseño de una mejor arquitectura.
Aunque la velocidad con la que se ejecutan los programas de aplicación en computadoras construídas con procesadores CISC ha ido en aumento, ese aumento de velocidad no es atribuíble a la inclusión de conjuntos de instrucciones complejos en su repertorio, considerando que las computadoras construídas con procesadores RISC también han aumentado su velocidad pero sin inflar su conjunto básico de instrucciones. Si el aumento de velocidad en las computadoras CISC no es atribuíble en forma directa a conjuntos de instrucciones cada vez más grandes y sofisticados en los procesadores que están siendo construídos, ¿entonces de dónde viene el aumento en velocidad? Resulta que, más que un aumento en la velocidad de procesamiento ocasionado por conjuntos de instrucciones que eleven la computadora al nivel de una computadora CISC, el aumento en la velocidad de procesamiento se debe en buena medida a un aumento en la velocidad (medida en la frecuencia de los “pulsos de reloj”) a la cual opera el procesador en sí. Para fines comparativos, a principios del año 2000 un microprocesador típico como el AMD K6 podía operar con una frecuencia de 350 MHz (350 Megahertz, ó 350 millones de ciclos por segundo) en los “pulsos de reloj”, con una velocidad de 500 MHz disponible en familias selectas de avanzada. Diez años después, la velocidad había aumentado y estaba en el orden de los Gigahertz, siendo superior a 1 GHz (mil millones de ciclos por segundo). Esto representa una rapidez dos veces mayor en el tiempo de procesamiento, lo cual se traduce en una reducción a la mitad del tiempo usual en la ejecución de programas de aplicación tales como procesadores de texto y programas de diseño gráfico como AutoCAD o programas científicos como Mathematica. Estos aumentos de velocidad se han dado trabajando única y exclusivamente sobre la microelectrónica del circuito integrado, teniéndose que lidiar con fenómenos físicos que a frecuencias extremadamente altas empiezan a distorsionar las señales de los pulsos eléctricos, al entrar en acción parámetros físicos tales como la capacitancia eléctrica (la cual, por pequeña que sea, empieza a actuar como un corto circuito a frecuencias sumamente elevadas) o como la inductancia (la cual, por pequeña que sea, empieza a actuar como una resistencia, o mejor dicho como una reactancia o impedancia, hablando en términos propios de la ingeniería electrónica) que se opone al paso de la corriente eléctrica a frecuencias cada vez mayores. Incluso la autoinductancia de una línea de conducción eléctrica, sin necesidad de que el hilo conductor esté enrollado a manera de resorte para aumentar el efecto, se vuelve importante al operar en estas frecuencias que son propias de señales caracterizadas como microondas. Por si esto no fuera suficiente, las capacitancias e inductancias parasíticas que siempre están presente se pueden combinar para ocasionar oscilaciones autosostenibles en ciertas partes del sistema, sobre todo cuando hay retroalimentaciones que ocasionan que tales oscilaciones inesperadas se puedan sostener por cuenta propia mientras haya energía aplicada al circuito integrado. Irónicamente, el aumento en la densidad de los circuitos electrónicos con la consecuente disminución en las longitudes de los hilos conductores de electricidad se encarga de hacer a un lado algunos de estos efectos de naturaleza eléctrica en virtud de que la magnitud de los parámetros eléctricos dependen de la longitud de los hilos conductores, la cual se va reduciendo al ir disminuyendo las longitudes en virtud de la microminiaturización.
Pero el aumento continuo en la velocidad de los tiempos de procesamiento no ha resultado únicamente de mejoras continuas en el diseño de los circuitos electrónicos que han permitido elevar la frecuencia de los pulsos de reloj de los megahertz a los gigahertz. El otro factor igualmente importante es la disponibilidad de memorias cada vez más densas que hacen ver a las memorias RAM de 32 kilobytes de las primeras computadoras como algo casi risible. Cuando se cuenta con una memoria pequeña y hay que ejecutar programas que no caben en la memoria, se vuelve necesario subdividir el programa en “páginas” de modo tal que se carge en la memoria una página para ser ejecutada, tras lo cual se saca la primera página y se carga la segunda página conservando los resultados del procesamiento de la primera página, tras lo cual se saca la segunda página conservando los resultados del procesamiento de las primeras dos páginas, y así sucesivamente. En esto consiste el viejo truco de los “traslapes” o overlays (se pronuncia “overleis”), y es algo costoso en lo que a tiempos de ejecución se refiere, ya que hay que estar cargando constantemente páginas del disco duro a la memoria y de la memoria al disco duro según se requiera. Pero cuando se tiene suficiente memoria RAM disponible, no es necesario estar cargando y estar alternando entre pedazos del programa ejecutable, se puede cargar todo el programa ejecutable en la memoria RAM de la máquina, produciendo un aumento dramático en la velocidad de procesamiento del programa de aplicación.
Quienes se oponen a la filosofía de construír procesadores que son cada vez más complejos en virtud de que implementan conjuntos de instrucciones cada vez más sofisticados argumentan que puesto que no hay mucho que ganar en hacer tal cosa, y puesto que la razón principal por hacer tal cosa era el alto costo de las memorias RAM en otros tiempos, lo cual ha dejado se ser un obstáculo con la caída dramática en los costos de las memorias RAM, lo más cuerdo consiste en tratar de mantener el conjunto de instrucciones lo más sencillo posible, dejándole a los creadores del software el peso de diseñar programas que consuman los recursos de la memoria RAM en vez de consumir los recursos internos del procesador.
Así pues, todavía hasta la fecha, tenemos dos alternativas opuestas y contrastantes en el diseño de los procesadores contemporáneos, RISC y CISC.
La empresa Intel, la cual ya acostumbró a su clientela a estar esperando en cada introducción de una nueva familia de procesadores conjuntos más amplios y sofisticados de instrucciones, por meras cuestiones de mercadotecnia se aferra a la filosofía de diseño CISC. Presentar siempre procesadores que mantengan un mismo conjunto reducido de instrucciones con cambios mínimos va en contra de su política de dejar con la boca abierta a los compradores potenciales de sus productos. Se ha dicho que la única empresa que realmente se aferra a la filosofía de diseño CISC es Intel. Pero aunque sea la única, por varias décadas ha sido la que surte la gran mayoría del mercado mundial de procesadores construídos como circuitos integrados. Y su principal competidor, AMD, no quiere quedar atrás, y por el contrario, desea mantener sus productos compatibles con los procesadores Intel, ya que al hacer tal cosa AMD garantiza que todos los sistemas operativos construídos por Microsoft, la empresa fabricante de sistemas operativos más grande del mundo, que puedan correr y ejecutarse en los procesadores fabricados por Intel, podrán correr y ejecutarse también en los procesadores AMD sin problema alguno. De este modo, el debate CISC contra RISC no es una mera cuestión que se resuelva sobre bases puramente técnicas y consideraciones teóricas propias de las ciencias de la computación, en el debate entran también intereses fuertes que van a defender sus nichos a capa y espada. Esto garantiza que el debate continuará por buen tiempo, aunque se puede suponer que tarde o temprano llegará el momento en el cual Intel, ni siquiera con sus vastos y poderosos recursos económicos y técnicos, podrá seguir enredando la microprogramación de la unidad de control más de lo que ya está.